
가디원 서브스테이션 v2.0이 정식으로 론칭된 지 이제 한 달이 거의 다 되어가는 듯합니다. 실제 고객사 현장에 도입되어 활발히 사용되고 있는 제품을 보니 감회가 새로운데요.
이번 스토리에는 해당 제품을 개발하며 새로운 기능을 만드는 와중에, Python 기반 백엔드 서버에서 Multi Thread 와 Multi Processing 병렬 처리를 활용해, AI 알고리즘 연산 동시성 이슈를 고민하고, AWS Lambda 비동기로 극복했던 과정을 담아보았습니다.
1. 이슈 해결을 위한 고민
가디원 서브스테이션 v2.0을 개발하던 중,기존 백엔드 서버에서 동작하던 AI 연산부에서 치명적인 이슈를 발견한 적이 있었습니다.
해당 이슈를 해결하기 위해 스프린트 플래닝 과정에서 Product Owner와 당시 옆에 있었던 프론트엔드 리드, 그리고 팀 내 개발자 등 180cm가 넘는 거구들과 함께 화이트 보드 앞에서 열띤 토의를 했습니다. (심리적 압박감 무엇..?) 결론적으로는 아래와 같은 이슈로 인해 백엔드 서버에서 AI를 분리하기로 결정했습니다.
가디원 서브스테이션에서 AI 알고리즘이 동작하는 순간은 크게 3가지로 분류됩니다.
•
신규 고객이 서브스테이션에 변압기 및 DGA 데이터를 처음 등록할 때 (Bulk Upload)
•
기존 변압기의 DGA 가스 이력을 새로 추가할 때 (Web Upload)
•
작업자가 변압기 점검일지를 작성할 때
이 중 3번째 점검일지를 작성하는 과정에서, 여러 사람이 점검일지를 동시에 작성하게 되면, AI 알고리즘도 동시에 여러 개가 돌아가기를 기대했지만, 처음 알고리즘을 개발하던 당시에는 동시 실행이 불가능한 구조였습니다.
즉, 백엔드 서버가 동시에 여러개의 API 요청을 받을 수 있고, 동시에 여러개의 DB 트랜잭션도 가능하지만, AI 연산은 오직 1 개의 프로세스만 가능한 구조였습니다.

기존 동작 Process
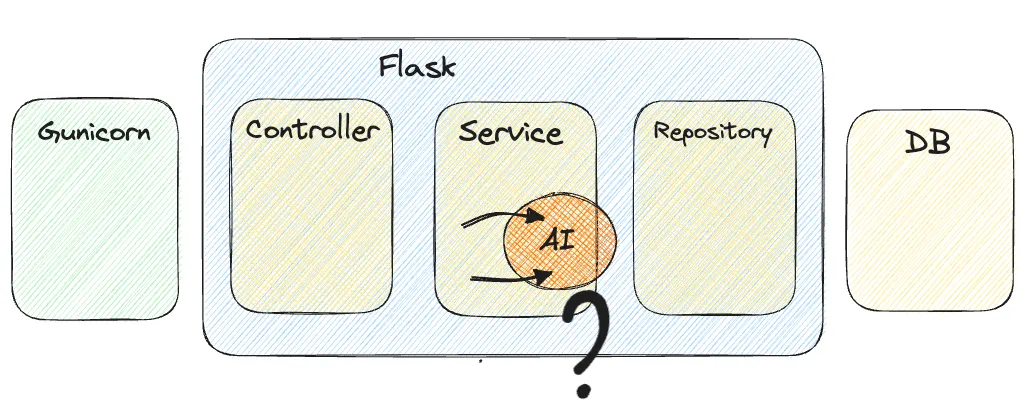
AI 연산 중에 또다른 AI 요청이 들어오면 Exception…
어떻게 해결할 수 있을까?
AI 알고리즘 연산부를 동시 처리가 가능하도록 바꾸자!
해당 이슈를 처음 발견했을 때는 AI 연산 코드를 동시처리 되도록 수정하면 되지 싶어서 해당 코드를 훑어봤지만, 하나의 함수에 600~700 줄이 넘는 구조의 코드를 리팩토링할 엄두가 나지 않았고… ADSP 라는 자잘한 데이터 분석 자격증을 딴적은 있지만, 도메인 지식도 부족하고 실무에서 사용하는 AI 코드를 건드리는 것은 Risk 가 큰, 현 스프린트 일정내에 처리 하기에 배보다 배꼽이 더 큰 상황이었습니다.
AI 연산을 큐에 쌓아두자!
AI 연산하는 부분을 큐에 쌓아 두어서, 순차적으로 돌리게 하자라는 의견도 나왔습니다. 얼핏 보면 그럴듯한 해결 방법으로 생각할 수 있었지만, 이 방법은 가디원 서브스테이션 제품의 사용자가 많아지면 많아질수록 큐 대기 시간이 증가하게 되는 문제가 있습니다. 트래픽이 많아지거나 시간이 지날수록 고객에게 좋은 서비스를 제공하지 못하는 구조는 개발자로서의 자존심이 허락하지 않습니다.
Backend 서버와 AI 를 분리하자!
클린 아키텍처나 DDD 관련 서적을 찾아보면, 개발을 할 때 유지보수 측면에서, 코드 간 응집도는 높이고 결합도는 낮게 설계 하도록 권장하고 있습니다.
관련해서 평소에도 백엔드와 AI 간에 관심사의 분리가 필요하다고 생각했고, 기존 DB 와 강결합되어 있었던 AI 코드를 간섭이 없는 pure 함수 형태로 떼어내서 이 AI 연산부를 별도의 여러 대의 서버에서 구현하게 하면 구조적으로 해결이 가능할 것으로 보였습니다.
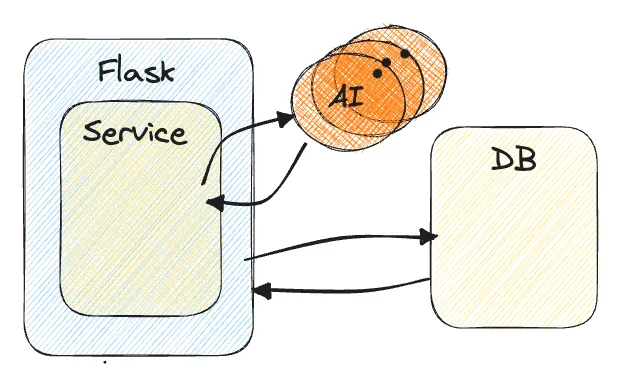
AI 연산부를 AWS Lambda 로 분리
2. Lambda 도입
AI 서버를 분리하기에 앞서, “하나의 EC2 서버에 쿠버네티스 환경을 구현해 여러 AI 도커 컨테이너를 띄울 것인가?” “2,3 개의 EC2 서버를 띄울 것인가” 아니면, “Lambda를 사용해서 함수 호출 시에만 비용이 나가게 할 것인가” 에 대한 고민이 있었습니다.
개발 난이도만 본다면, 여러 대의 EC2 를 사용해서 구현하는 게 가장 쉽고, 쿠버네티스 그리고 Lambda 순으로 느껴졌지만, 비용적인 측면을 고려한다면 압도적으로 Lambda가 합리적이었습니다. 또한 최소한의 비용으로 최대의 효율이 뽑아내도록 하는 것이 백엔드 개발자로서 숙명이라 생각해 Lambda 로 결정했습니다.

2.1 EFS (Elastic File System)
Lambda를 사용하기에 앞서, 파이썬 코드를 Lambda로 빼기 위해서는 필요한 pip Python 라이브러리 모듈을 설치해 주어야 하는데, AI 분야에서 사용하는 라이브러리는 대게 사이즈 덩치가 상당한 편이었습니다.
Lambda 에 실행 가능한 형태로 올리기 위해서는 Zip 형태의 압축파일로 올리거나, S3 Bucket 에 올려야 하는데, 각각 50Mb, 160Mb 의 제한이 있었고, 프로젝트 전체 2GB 가 넘어가는 녀석을 Lambda 에 올리기 위해서는 대안이 필요했습니다.
DevOps 팀의 열정적인 분에게 찾아가 조언을 받기론 AWS EFS (Elastic File System)을 활용해서 실제 설치된 패키지는 마운트된 ec2 에서 가져오도록 하면 해결이 가능할 것 같다는 조언을 받고, 이를 구성하기 까지도 많은 시행착오가 있었지만, 덕분에 Lambda를 돌릴 수 있는 환경을 구축했습니다.
이렇게 해도 사이즈가 부족하다면 Lambda Layer를 고려해보려 했지만 다행히도 성공적이었습니다.
관련 자료

2.2 Lambda 함수 마운트 폴더 설정
import sys
sys.path.append("/mnt/efs/packages") # 마운트 폴더 설정
from MtrAPI import MtrAPI
def lambda_handler(event, context):
ai_processing_result = MtrAPI(event)
return ai_processing_result
JavaScript
복사
이렇게 기존 가디원 서브스테이션 제품의 AI 동시성 연산 이슈에 대해서 구조적으로 Backend 파트와 AI 연산 파트를 분리해서 결합도를 낮췄고, 분리된 AI 파트를 aws Lambda 를 활용해서, 별도의 AI 서버를 통한 로드밸런싱 없이, 다중 처리가 가능하도록 수정했습니다.
새로운 이슈의 등장!
해당 기능을 만들면서, 단일 변압기 설비에 대한 AI 연산이 많이 발생할 것으로 기대했으나, 시간이 지나 추가된 기획에 의하면 오히려 단일 설비보다, 회사 전체 설비에 대한 AI 연산을 돌리는 기능이 많아질 것으로 확인되었습니다.
설비 당 AI 연산이 약 4~5 초 정도 걸리는 것에 비해, 회사 별 전체 설비로 이어진다면, 구조적인 개선 뿐만 아니라 성능 개선 또한 같이 이루어져야 했습니다.
Boto3 비동기
처음에는 비동기로 처리하는 것을 고려해봤습니다.
AWS 에서 Lambda를 공식적으로 지원해주는 Python 라이브러리로는 Boto3가 있습니다. 아래와 같은 방식으로 Boto3 Session 을 연동하고, AI 연산 부분을 Lambda에서 동기식으로 정상 동작 하는 것을 확인할 수 있었습니다.
# 동기 방식
def execute_lambda(payload):
lambda_client = get_boto3_session()
function_name = "substation_lambda"
# Lambda 함수 실행
response = lambda_client.invoke(
FunctionName=function_name, Payload=json.dumps(payload)
)
result = json.loads(response["Payload"].read().decode("utf-8"))
return result
# 비동기 방식
async def execute_lambda_async(payload):
lambda_client = get_boto3_session()
# Lambda 함수 실행
response = await asyncio.get_running_loop().run_in_executor(
None,
lambda_client.invoke,
{"FunctionName": "substation_lambda", "Payload": payload},
)
return response["Payload"].read().decode("utf-8")
JavaScript
복사
다만 성능과 동시성 처리를 위해 비동기 방식으로 처리를 하고 싶었고 여러 시도를 해본 결과, boto3 ‘1.26.94’ 버전에서는 공식 매뉴얼(링크)에서도 deprecated 되었다고 명시되었고, 실제로 응답 코드만 받아올 수 있었습니다.
여기까지 오기에도 많은 시간과 에너지를 소모 했지만 해당 방법으로도 뭔가 2% 부족했습니다. 실제로 많은 변전소 설비와 DGA 데이터를 담고 있는 엑셀 파일을 통해 (Bulk Upload) 시에 동기식으로 연산을 하게 되면, 아래와 같은 시간이 소요되었습니다.
[ 동기식으로 AWS Lambda 구현 시 동작 속도 -> 정상 실행]
- 실행 시간: 760.1468849182129초
start_time = time.time()
for asset in asset_list:
# AI Input 데이터 추출
mtrbodydga_dict_data = get_mtr_pre_data_list(session, asset.id)
# AI 연산 시작
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
# AI 연산 결과 저장
MtrAPI_RusultUpload(session, result.get("response"))
end_time = time.time()
elapsed_time = end_time - start_time # 경과 시간 계산
print(f"실행 시간: {elapsed_time}초")
JavaScript
복사
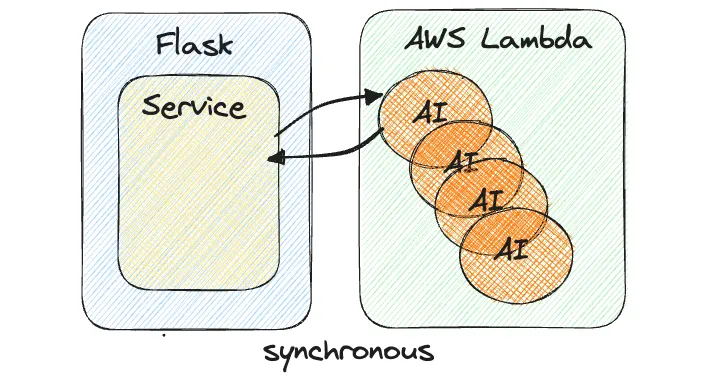
여러 개의 AI 연산을 동기식으로 처리
3. 병렬 처리
Lambda를 사용하기 위한 Boto3 라이브러리에서 비동기가 지원이 되지 않는다면 파이썬 자체적으로 Thread 와 Multi Processing을 활용해 구현 해보기로 했습니다.
참고로 보통 아래의 상황에서는 쓰레드나 프로세스를 사용해서 해당 작업들을 병렬로 실행하는 것을 권장합니다.
애플리케이션이 I/O 를 처리할 때는 운영 체제가 스트림을 처리해서 결과를 돌려줄 때까지 계속 대기한다. 이 시간 동안 애플리케이션은 멈춰 있다.
애플리케이션이 CPU를 사용하여 계산할 때 CPU 중 하나만 사용한다. 다른 CPU는 유휴상태로 있다.
3.1 Thread VS Process
다만 Python 언어에는 C#, Java와 달리 GIL (global Interpreter lock) 이란 골칫거리가 있습니다.
GIL은 파이썬 전역 인터프리터 락의 줄임말로, Python 이 Byte 코드를 실행할 때마다 Thread 에 잠금이 걸리게 됩니다. 그러다 보면 Thread 여러 개로 애플리케이션을 확장 하더라도 GIL 로 인해 모든 Thread가 이 GIL 를 차지하기 위해서 경합합니다. 그래서 Byte 코드를 실행하는 함수를 여러 Thread 에서 돌리게 되면 GIL 경합으로 인해 성능이 떨어지게 됩니다.
반면에 Multi Processing를 사용하게 되면 한번에 많은 작업을 실행할 수 있습니다. GIL 이 관여하지 않으므로 Thread보다 빠르지만 Process 사이에는 어떤 메모리 공간도 공유되지 않기 때문에 프로세스에서 다른 프로세스로 전환하기 위해서는 상태 없이(stateless) 동작할 수 있는 조건에서 해야 합니다. 또한 프로세스를 사용하게 되면 네트워크 연결 비용이 더 증가할 수 있는 단점이 있습니다.
정리하면 I/O 작업을 동시에 처리할때는 Thread 가 효율적이고 CPU 사용량을 최대로 끌어올리려면 많은 Process를 사용 하는게 효율적 입니다.
Lambda 같은 경우도 Backend → Lambda 로 I/O 작업이기에 Thread 가 좀 더 효율적 일거라 기대했습니다. 다만 Python 의 GIL 에 의한 성능 저하가 기대되어 Multi Thread 와 Process 일 때 각각 비교해보면서 더 효율적인 것을 사용해보기로 했습니다.
3.2 병렬 처리 오류
해당 파이썬 코드에서 사용할 병렬 처리 라이브러리로 ‘concurrent.futures’ 라이브러리를 활용했습니다. 다만 기존 코드에서 Lambda 를 돌릴 함수 부분과 해당 함수에 Input 값을 넣어줄 부분을 묶어서 하나의 병렬 처리를 위한 함수로 구현했지만 이렇게 했을 경우, Thread와 Process 모두 동일한 에러를 발생했습니다.
[ProcessPoolExecutor 사용 시 문제]
• TypeError("'dict' object is not callable")
with futures.ProcessPoolExecutor(max_workers=4) as executor:
futures_list = [
executor.submit(process_asset(session, data)) for data in asset_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
... 핵심 부분
def process_asset(session, asset):
try:
# AI 연산 Input 데이터 가공
mtrbodydga_dict_data = get_mtr_pre_data_list(session, asset.id)
# AI 연산 시작
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
return result
JavaScript
복사
[TreadPoolExecutor 사용 시 문제]
• TypeError("'dict' object is not callable")
# 4. AI 연산 Thread 사용
with futures.ThreadPoolExecutor(max_workers=4) as executor:
futures_list = [
executor.submit(process_asset(session, data)) for data in asset_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
... 핵심 부분
def process_asset(session, asset):
try:
# AI 연산 Input 데이터 가공
mtrbodydga_dict_data = get_mtr_pre_data_list(session, asset.id)
# AI 연산 시작
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
return result
JavaScript
복사
가능성이 있어 보이는 코드에는 모두 예외 처리를 했음에도, 예외를 타지 않는 에러가 발생했고, 아래와 같이 ChatGPT 의 도움을 받아보니 아래 공유 데이터에 대한 이슈가 해결의 실마처럼 보였습니다.

“스레드 간에 공유되는 데이터에 대한 접근 충돌이 있는지 확인합니다. 스레드 간의 동시 접근을 막기 위해 동기화 메커니즘을 사용할 수 있습니다.”
3.3 병렬 처리 해결
GPT의 도움을 받아 고민해보니, 기존 병렬 처리로 사용될 process_asset 함수가 마음에 걸렸습니다.
Lambda 함수를 실행하기 전 Lambda 의 Input 값을 만들어 주던 get_mtr_pre_data_list(session, asset.id) 함수가, 공유 데이터에 대한 이슈와 더불어 db session 까지 물고 있었기에 의심의 여지가 강하게 보였고, 전반적인 레거시 코드를 수정 함으로써, 병렬 처리로 사용할 process_asset 함수를 Lambda 실행 부분만 분리해내어 정상 실행을 확인할 수 있었습니다.
[Before]
def process_asset(session, asset):
# AI 연산 Input 데이터 가공
mtrbodydga_dict_data = get_mtr_pre_data_list(session, asset.id)
# AI 연산 시작
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
return result
JavaScript
복사
[After]
def process_asset(mtrbodydga_dict_data):
# AI 연산 시작
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
return result
JavaScript
복사
3.4 병렬 처리 성능 비교
[4개의 Thread로 돌릴 때 시간 소모]
•
TreadPoolExecutor - 4 worker
•
실행 시간: 197.9756360054016초
start_time = time.time()
# 4.1 AI 연산 데이터 추출
ai_input_data_list = get_mtr_pre_data_list(session, company_id)
# 4.2 AI Lambda 연산
with futures.ThreadPoolExecutor(max_workers=4) as executor:
futures_list = [
executor.submit(process_asset, data) for data in ai_input_data_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
end_time = time.time()
elapsed_time = end_time - start_time # 경과 시간 계산
...
def process_asset(mtrbodydga_dict_data):
result = execute_lambda(mtrbodydga_dict_data)
if result.get("status") != 200:
raise Exception("Ai Lambda 연산 중에 에러가 발생했습니다")
return result
JavaScript
복사
[8개의 Thread로 돌릴 때 시간 소모]
•
TreadPoolExecutor - 8 worker
•
실행 시간: 126.87955212593079초
start_time = time.time()
# 4.1 AI 연산 데이터 추출
ai_input_data_list = get_mtr_pre_data_list(session, company_id)
# 4.2 AI Lambda 연산
with futures.ThreadPoolExecutor(max_workers=8) as executor:
futures_list = [
executor.submit(process_asset, data) for data in ai_input_data_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
end_time = time.time()
elapsed_time = end_time - start_time # 경과 시간 계산
JavaScript
복사
[4개의 Process로 돌릴 때 시간 소모]
•
ProcessPoolExecutor - 4 worker
•
실행 시간: 276.74906373023987초
start_time = time.time()
# 4.1 AI 연산 데이터 추출
ai_input_data_list = get_mtr_pre_data_list(session, company_id)
# 4.2 AI Lambda 연산
with futures.ProcessPoolExecutor(max_workers=4) as executor:
futures_list = [
executor.submit(process_asset, data) for data in ai_input_data_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
end_time = time.time()
elapsed_time = end_time - start_time # 경과 시간 계산
print(elapsed_time)
JavaScript
복사
[8개의 Process로 돌릴 때 시간 소모]
•
ProcessPoolExecutor - 8 worker
•
실행 시간: 212.99634408950806초
start_time = time.time()
# 4.1 AI 연산 데이터 추출
ai_input_data_list = get_mtr_pre_data_list(session, company_id)
# 4.2 AI Lambda 연산
with futures.ProcessPoolExecutor(max_workers=8) as executor:
futures_list = [
executor.submit(process_asset, data) for data in ai_input_data_list
]
# 5. AI 알고리즘 연산 결과 저장
for future in futures_list:
result = future.result()
if result is not None:
MtrAPI_RusultUpload(session, result.get("response"))
end_time = time.time()
elapsed_time = end_time - start_time # 경과 시간 계산
print(elapsed_time)
JavaScript
복사
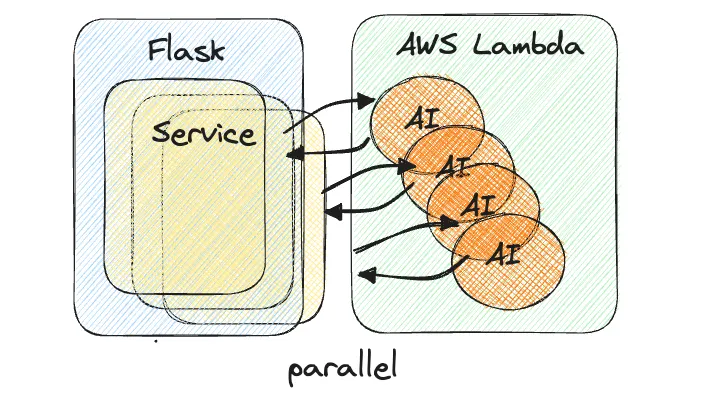
여러 개의 AI 연산을 병렬로 처리
4. 마치며
결과적으로 기존의 가디원 서브스테이션 제품에서 동시에 AI 연산을 할 수 없었던 근본적인 문제를 Lambda를 활용해서 동시다발적으로 처리할 수 있도록 아키텍처를 변경했고, 예상했었던 대로 I/O 작업을 하는 병렬 처리 작업에서는 Multi Process보다 Multi Thread가 성능적인 이점을 가진다는 것을 확인할 수 있었습니다.

Excel Bulk Upload 기준 성능 향상 지표
이런 과정을 통해 개발된 가디원 서브스테이션이 어떤 편리한 기능을 갖추게 되었는지 궁금하시다면, 아래 링크를 통해 더 자세히 확인해보실 수 있습니다.


이 글을 쓴 사람

장 진 수 | 백엔드 개발자
제조 분야 대기업에서 수많은 설비 데이터를 가공하고 운영해왔습니다.
CTO (Chief Technology Officer)를 꿈꾸며 마주하는 이슈를 풀어가기 위해 아키텍처와 컨셉을 고민하고, 이런 노력이 제품에 반영될 수 있는 환경을 찾아 스타트업인 원프레딕트에 합류하게 되었습니다.
장진수님이 쓴 또 다른 글 보러가기
원프레딕트 홈페이지
https://onepredict.ai/
원프레딕트 블로그
https://blog.onepredict.ai/
원프레딕트 기술 블로그
https://tech.onepredict.ai