
1편을 읽고 오시면 더 유익하게 이 글을 즐기실 수 있습니다.
이전 글에서 정리한 지표를 보면 Raw SQL로 사용했을 경우 ORM 대비 좋은 성능을 기대할 수 있습니다. 이번 글에서는 원프레딕트 Pro-Serve팀원분께 받은 ‘ORM으로 사용 시 좀 더 최적화하는 방법에 대한 힌트’와 ORM을 활용해서 DB 트랜잭션을 처리할 경우 성능을 개선할 수 있는 방법, 그리고 ORM이 가진 특별한 장점에 대해서 이야기하려고 합니다.
*DB 서버는 이전 편의 ‘네트워크 트래픽 이슈’를 고려하지 않기 위해서 Local PC에서 진행됐습니다.
1. 성능 비교 툴
성능에 대한 지표로는 2023년 Naver Deview 의 ‘ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인’ 에서 영감을 얻었던 line-profiler’ 라이브러리를 활용해서 비교를 진행했습니다. (고마워요 갓 네이버 '문주혁’님…)
2-1. 성능 개선 포인트: Lambda 활용
Sqlalchemy ORM 에서 성능을 개선할 수 있는 방법으로 Lambda를 사용하는 방법이 있습니다. Lambda 방식은 미리 적어둔 ORM 코드 블록을 미리 쿼리로 가공한 함수처럼 지정해서 사용하는 방식입니다.
Sqlalchemy Lambda를 활용한 테스트 비교는 이전 글에서 작성한 ‘enterprise-mtr-grade-status’ API 의 일부분에 대해서만 진행했습니다. 성능에 대한 지표로는 2023년 Naver Deview 의 ‘ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인’에서 영감을 얻었던 line-profiler 라이브러리를 활용해서 비교를 진행했습니다.
1. 회사명을 조회
2. 회사별 라이센스 조회 (외부 API)
3. 변압기 설비별 모든 DGA 가스 측정일과 직전 측정일 추출
Before (ORM)
Total time: 1.5103 s
File: line_profiler_test_2.py
Function: test_func at line 34
Line # Hits Time Per Hit % Time Line Contents
==============================================================
34 def test_func():
35 1 13000.0 13000.0 0.0 Session = sessionmaker(bind=engine)
36 1 138000.0 138000.0 0.0 session = Session()
37 1 0.0 0.0 0.0 company_id = 16
38
39 # 회사명 조회
40 1 0.0 0.0 0.0 company_name = (
41 1 78492000.0 78492000.0 5.2 session.query(Company.company_name)
42 1 147000.0 147000.0 0.0 .filter(Company.id == company_id)
43 .first()
44 .company_name
45 )
46
47 # 회사별 라이센스 조회
48 1 673974000.0 673974000.0 44.6 available_licenses = LicenseUtils.license_check_all(company_name=company_name)
49
50 # asset 별 모든 측정일과 이전 측정일 추출
51 1 0.0 0.0 0.0 asset_info = (
52 1 196459000.0 196459000.0 13.0 session.query(
53 1 109000.0 109000.0 0.0 Asset.id.label("asset_id"),
54 1 34000.0 34000.0 0.0 Asset.asset_name.label("asset_name"),
55 1 10000.0 10000.0 0.0 DataMtrBodyDga.acquisition_date.label("acquisition_date"),
56 1 345000.0 345000.0 0.0 func.lead(DataMtrBodyDga.acquisition_date, 1)
57 .over(
58 1 2000.0 2000.0 0.0 partition_by=[Asset.id, Asset.asset_name],
59 1 65000.0 65000.0 0.0 order_by=DataMtrBodyDga.acquisition_date.desc(),
60 )
61 1 1000.0 1000.0 0.0 .label("prev_acquisition_date"),
62 )
63 1 0.0 0.0 0.0 .select_from(Asset)
64 1 66000.0 66000.0 0.0 .join(DataMtrBodyDga, DataMtrBodyDga.asset_id == Asset.id)
65 .filter(
66 1 131000.0 131000.0 0.0 Asset.company_id == company_id,
67 1 104000.0 104000.0 0.0 Asset.asset_type == "MTR",
68 1 21173000.0 21173000.0 1.4 Asset.serial_no.in_(available_licenses),
69 )
70 1 24000.0 24000.0 0.0 .order_by(Asset.id, Asset.asset_name, DataMtrBodyDga.acquisition_date.desc())
71 .all()
72 )
73
74 1 539010000.0 539010000.0 35.7 print(asset_info)
Python
복사
line-profiler에 소요된 총 시간은 1.5103초였습니다.
After (ORM Lambda)
Total time: 0.795556 s
File: line_profiler_test_3.py
Function: test_func at line 34
Line # Hits Time Per Hit % Time Line Contents
==============================================================
34 def test_func():
35 1 12000.0 12000.0 0.0 Session = sessionmaker(bind=engine)
36 1 134000.0 134000.0 0.0 session = Session()
37 1 0.0 0.0 0.0 company_id = 16
38
39 # 회사명 조회
40 1 53103000.0 53103000.0 6.7 company_name = (
41 1 1000.0 1000.0 0.0 lambda session, company_id: session.query(Company.company_name)
42 .filter(Company.id == company_id)
43 .first()
44 .company_name
45 1 0.0 0.0 0.0 )(session, company_id)
46
47 # # 회사별 라이센스 조회
48 1 716299000.0 716299000.0 90.0 available_licenses = LicenseUtils.license_check_all(company_name=company_name)
49
50 # # asset 별 모든 측정일과 이전 측정일 추출
51 1 14105000.0 14105000.0 1.8 asset_info = (
52 1 1000.0 1000.0 0.0 lambda session, company_id, available_licenses: session.query(
53 Asset.id.label("asset_id"),
54 Asset.asset_name.label("asset_name"),
55 DataMtrBodyDga.acquisition_date.label("acquisition_date"),
56 func.lead(DataMtrBodyDga.acquisition_date, 1)
57 .over(
58 partition_by=[Asset.id, Asset.asset_name],
59 order_by=DataMtrBodyDga.acquisition_date.desc(),
60 )
61 .label("prev_acquisition_date"),
62 )
63 .select_from(Asset)
64 .join(DataMtrBodyDga, DataMtrBodyDga.asset_id == Asset.id)
65 .filter(
66 Asset.company_id == company_id,
67 Asset.asset_type == "MTR",
68 Asset.serial_no.in_(available_licenses),
69 )
70 .order_by(Asset.id, Asset.asset_name, DataMtrBodyDga.acquisition_date.desc())
71 1 1000.0 1000.0 0.0 )(session, company_id, available_licenses)
72
73 1 11900000.0 11900000.0 1.5 print(asset_info)
Python
복사
line-profiler에 소요된 총 시간은 0.795556초였습니다.
Lambda를 사용하지 않는, 회사별 라이선스를 조회하는 외부 API에 대해서는 각각 44%, 90% 의 부하를 차지할 만큼 ORM 보다 Lambda를 활용한 방식이, 대략적으로 1.5103 → 0.795556초로 약 0.8초 정도 (47%) 성능에 대한 이점이 있는 것으로 나왔습니다.
해당 테스트를 진행하면서, ‘오? Lambda를 활용하면 ORM으로 성능도 잡을 수 있는 희망 회로를 그릴 수 있나?’라는 기대를 가져봤지만, 아쉽게도 실제 여러 테스트를 통해서 내린 결론으로는… 희망편도 절망편도 되지 못한 애매모호한 녀석이었다는걸 깨닫게 되었습니다. Lambda를 활용한 방식은 활용도가 제한적이었고. 이전 글에서 작성한 것과 같이 복잡한 ORM은 Lambda를 통해서 모두 구현할 수 없었습니다.
좀 더 구체적으로, 위에 작성 했던것과 같이 단순 테이블을 조인해서 사용하는 것은 Lambda로 가능하지만, 쿼리 블록을 또 다른 테이블처럼 만들어 subquery로 활용하는 것은 불가능했습니다.
믿었던 ChatGPT 와 30~40 번의 토론을 거쳤음에도 비슷한 답변만을 보여줬습니다.
ChatGPT 도 그럴듯한 답변에는 문법적인 오류가 있는 답변만 열거하는 식의 연속이었고, SQL 튜닝 관점에서 성능을 올리는 방법에 대한 답변을 마지막으로, 복잡한 쿼리는 Raw SQL 을 대체할 만한 녀석이 없었다는 것으로 결론을 지었습니다. 그래도 일반적인 OLTP 시스템의 경우는 좋은 성능 향상 도구가 될 거라 생각됩니다.
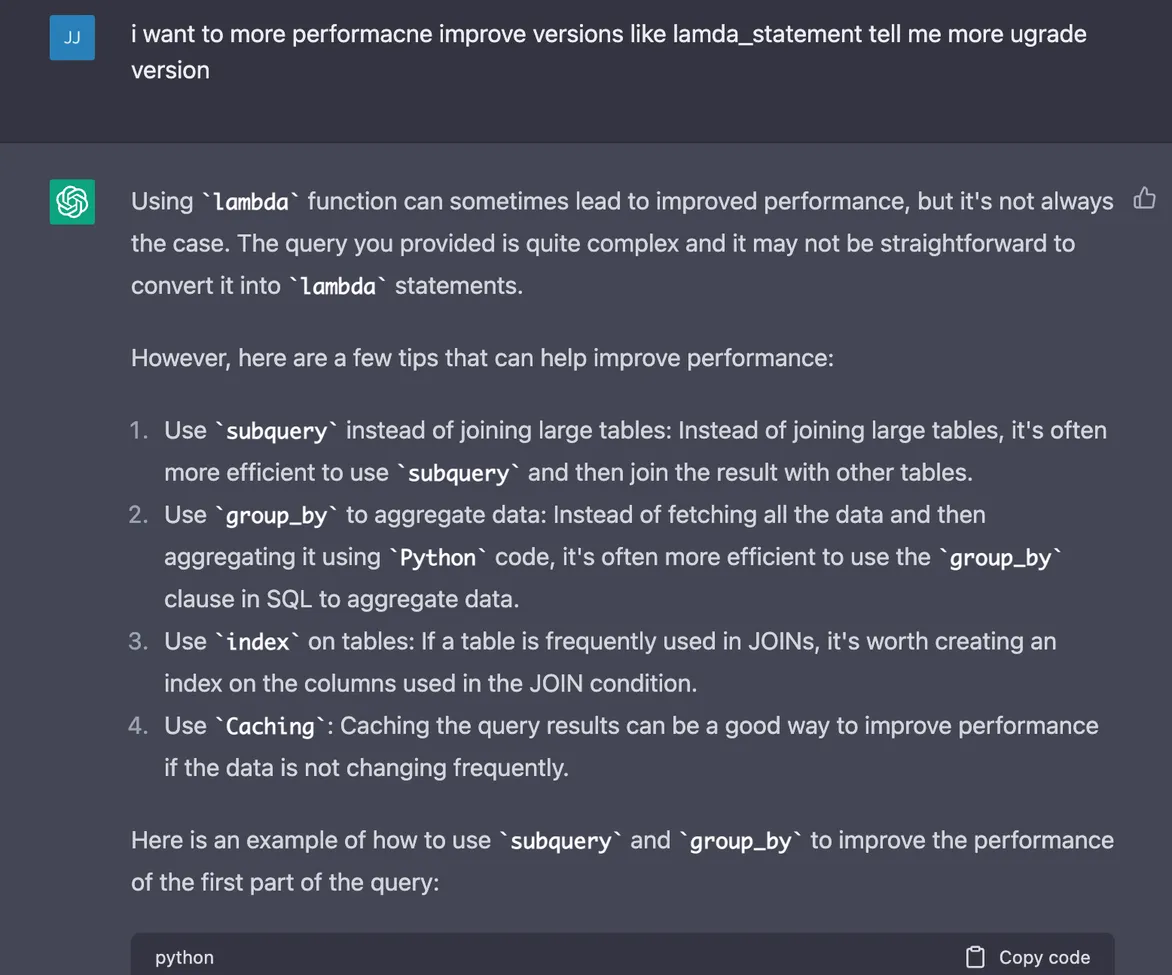
“Lambda 기능을 사용하면 때때로 성능이 향상될 수 있지만 항상 그런 것은 아닙니다. 귀하가 제공한 쿼리는 매우 복잡하며 람다 명령문으로 변환하는 것이 간단하지 않을 수 있습니다.”

“복잡한 SQL 쿼리에 Lambda 함수를 사용하면 코드를 읽고 유지관리하기 더 어려워질 수 있으므로 주의해서 사용해야 합니다.”
2-2. 성능 개선 포인트: View 테이블 활용
또 다른 성능 개선 포인트로는 ‘View’ 테이블을 활용하는 방법을 생각해봤습니다.
이전 편에서 사용한 쿼리처럼 License 서버에서 “available_license” list를 가져와 IN 절에서 사용하는 SQL 쿼리는 또 다른 View로 만들어 사용하기 어려운 점이 있지만, 이번에는 회사 ID를 사용해 설비의 상태를 가져오는 다른 SQL을 사용해서 비교를 해봤습니다.
Before (ORM)
Total time: 1.81674 s
File: line_profiler_test.py
Function: test_func at line 22
Line # Hits Time Per Hit % Time Line Contents
==============================================================
22 def test_func():
23 1 24000.0 24000.0 0.0 Session = sessionmaker(bind=engine)
24 1 146000.0 146000.0 0.0 session = Session()
25
26 1 1000.0 1000.0 0.0 company_id = 16
27
28 # asset 별 최신 DGA 측정일과 직전 측정일 조회
29 1 0.0 0.0 0.0 asset_info = (
30 1 151000.0 151000.0 0.0 session.query(
31 1 44000.0 44000.0 0.0 Asset.id.label("asset_id"),
32 1 1000.0 1000.0 0.0 Asset.asset_name,
33 1 4000.0 4000.0 0.0 DataMtrBodyDga.acquisition_date,
34 1 146000.0 146000.0 0.0 func.lead(DataMtrBodyDga.acquisition_date, 1)
35 .over(
36 1 1000.0 1000.0 0.0 partition_by=[Asset.id, Asset.asset_name],
37 1 0.0 0.0 0.0 order_by=[
38 1 1000.0 1000.0 0.0 Asset.id,
39 1 0.0 0.0 0.0 Asset.asset_name,
40 1 25000.0 25000.0 0.0 DataMtrBodyDga.acquisition_date.desc(),
41 ],
42 )
43 1 0.0 0.0 0.0 .label("prev_acquisition_date"),
44 )
45 1 0.0 0.0 0.0 .select_from(Asset)
46 .outerjoin(
47 1 0.0 0.0 0.0 DataMtrBodyDga,
48 1 20000.0 20000.0 0.0 Asset.id == DataMtrBodyDga.asset_id,
49 )
50 .filter(
51 1 43000.0 43000.0 0.0 Asset.company_id == company_id,
52 )
53 .order_by(
54 1 1000.0 1000.0 0.0 Asset.id,
55 1 0.0 0.0 0.0 Asset.asset_name,
56 1 12000.0 12000.0 0.0 DataMtrBodyDga.acquisition_date.desc(),
57 )
58 .subquery()
59 )
60
61 # asset 별 DGA 최신 측정날짜와 직전 측정날짜 조회
62 1 0.0 0.0 0.0 acq_date_by_asset = (
63 1 98000.0 98000.0 0.0 session.query(
64 1 165000.0 165000.0 0.0 asset_info.c.asset_id,
65 1 28000.0 28000.0 0.0 func.max(asset_info.c.acquisition_date).label("acquisition_date"),
66 1 38000.0 38000.0 0.0 case(
67 1 0.0 0.0 0.0 [
68 1 0.0 0.0 0.0 (
69 1 32000.0 32000.0 0.0 func.max(asset_info.c.prev_acquisition_date) == None,
70 1 14000.0 14000.0 0.0 func.max(asset_info.c.acquisition_date),
71 ),
72 1 0.0 0.0 0.0 (
73 1 23000.0 23000.0 0.0 func.max(asset_info.c.prev_acquisition_date) != None,
74 1 12000.0 12000.0 0.0 func.max(asset_info.c.prev_acquisition_date),
75 ),
76 ]
77 1 1000.0 1000.0 0.0 ).label("prev_acquisition_date"),
78 )
79 1 1000.0 1000.0 0.0 .group_by(asset_info.c.asset_id)
80 .subquery()
81 )
82
83 # 설비별 AI 프로세스 진행 여부
84 1 0.0 0.0 0.0 ai_process_state = (
85 1 104000.0 104000.0 0.0 session.query(
86 1 0.0 0.0 0.0 AiProcessStatus.asset_id,
87 1 8000.0 8000.0 0.0 literal("RUNNING").label("ai_process"),
88 )
89 1 27000.0 27000.0 0.0 .filter(AiProcessStatus.is_ai_process_finish == None)
90 1 0.0 0.0 0.0 .order_by(AiProcessStatus.asset_id)
91 .subquery()
92 )
93
94 # asset 의 DGA 날짜별 AI 진단 결과 조회
95 1 1000.0 1000.0 0.0 diag_info = (
96 1 143000.0 143000.0 0.0 session.query(
97 1 0.0 0.0 0.0 DataMtrBodyDga.asset_id,
98 1 0.0 0.0 0.0 DataMtrBodyDga.acquisition_date,
99 1 1000.0 1000.0 0.0 AiMtrBodyDga.ai_diagnosis_result,
100 )
101 1 0.0 0.0 0.0 .select_from(DataMtrBodyDga)
102 .outerjoin(
103 1 1000.0 1000.0 0.0 AiMtrBodyDga,
104 1 28000.0 28000.0 0.0 AiMtrBodyDga.data_mtr_body_dga_id == DataMtrBodyDga.id,
105 )
106 .subquery()
107 )
108
109 # asset 별 최신 DGA 측정일의 AI 진단 결과 조회
110 1 0.0 0.0 0.0 lts_query = (
111 1 136000.0 136000.0 0.0 session.query(
112 1 80000.0 80000.0 0.0 acq_date_by_asset.c.asset_id,
113 1 1000.0 1000.0 0.0 acq_date_by_asset.c.acquisition_date,
114 1 191000.0 191000.0 0.0 diag_info.c.ai_diagnosis_result,
115 1 54000.0 54000.0 0.0 ai_process_state.c.ai_process,
116 )
117 1 0.0 0.0 0.0 .select_from(acq_date_by_asset)
118 1 11000.0 11000.0 0.0 .join(diag_info, acq_date_by_asset.c.asset_id == diag_info.c.asset_id)
119 .outerjoin(
120 1 0.0 0.0 0.0 ai_process_state,
121 1 9000.0 9000.0 0.0 acq_date_by_asset.c.asset_id == ai_process_state.c.asset_id,
122 )
123 .filter(
124 1 10000.0 10000.0 0.0 acq_date_by_asset.c.acquisition_date == diag_info.c.acquisition_date,
125 )
126 .subquery()
127 )
128
129 # asset 별 직전 DGA 측정일의 AI 진단 결과 조회
130 1 0.0 0.0 0.0 prev_query = (
131 1 47000.0 47000.0 0.0 session.query(
132 1 1000.0 1000.0 0.0 acq_date_by_asset.c.asset_id,
133 1 0.0 0.0 0.0 acq_date_by_asset.c.acquisition_date,
134 1 0.0 0.0 0.0 diag_info.c.ai_diagnosis_result,
135 )
136 1 0.0 0.0 0.0 .select_from(acq_date_by_asset)
137 1 8000.0 8000.0 0.0 .join(diag_info, acq_date_by_asset.c.asset_id == diag_info.c.asset_id)
138 .filter(
139 1 8000.0 8000.0 0.0 acq_date_by_asset.c.prev_acquisition_date == diag_info.c.acquisition_date,
140 )
141 .subquery()
142 )
143
144 1 0.0 0.0 0.0 main_query = (
145 1 1799239000.0 1799239000.0 99.0 session.query(
146 1 4000.0 4000.0 0.0 Asset.id.label("asset_id"),
147 1 1000.0 1000.0 0.0 Asset.asset_name,
148 1 3000.0 3000.0 0.0 Site.id.label("site_id"),
149 1 0.0 0.0 0.0 Site.site_name,
150 1 0.0 0.0 0.0 Asset.voltage_low,
151 1 1000.0 1000.0 0.0 Asset.voltage_high,
152 1 0.0 0.0 0.0 Asset.capacity_low,
153 1 1000.0 1000.0 0.0 Asset.capacity_high,
154 1 0.0 0.0 0.0 Asset.manufacturer,
155 1 40000.0 40000.0 0.0 func.to_char(Asset.manufacturing_date, "YYYY-MM-DD").label(
156 1 1000.0 1000.0 0.0 "manufacturing_date"
157 ),
158 1 32000.0 32000.0 0.0 func.to_char(Asset.operating_date, "YYYY-MM-DD").label("operating_date"),
159 1 12000.0 12000.0 0.0 Asset.usage.label("usage"),
160 1 1000.0 1000.0 0.0 Asset.resource_id,
161 1 0.0 0.0 0.0 Asset.serial_no,
162 1 109000.0 109000.0 0.0 lts_query.c.acquisition_date,
163 1 32000.0 32000.0 0.0 case(
164 1 0.0 0.0 0.0 [
165 1 0.0 0.0 0.0 (
166 1 10000.0 10000.0 0.0 lts_query.c.ai_diagnosis_result
167 1 81000.0 81000.0 0.0 != prev_query.c.ai_diagnosis_result,
168 1 0.0 0.0 0.0 True,
169 ),
170 1 1000.0 1000.0 0.0 (
171 1 6000.0 6000.0 0.0 lts_query.c.ai_diagnosis_result
172 1 0.0 0.0 0.0 == prev_query.c.ai_diagnosis_result,
173 1 0.0 0.0 0.0 False,
174 ),
175 ]
176 1 0.0 0.0 0.0 ).label("is_state_changed"),
177 1 59000.0 59000.0 0.0 case(
178 1 0.0 0.0 0.0 [
179 1 21000.0 21000.0 0.0 (lts_query.c.ai_process == "RUNNING", "UNKNOWN"),
180 1 0.0 0.0 0.0 (
181 1 15000.0 15000.0 0.0 lts_query.c.ai_diagnosis_result == 0,
182 1 1000.0 1000.0 0.0 "NORMAL",
183 ),
184 1 0.0 0.0 0.0 (
185 1 12000.0 12000.0 0.0 lts_query.c.ai_diagnosis_result == 1,
186 1 1000.0 1000.0 0.0 "CAUTION",
187 ),
188 1 0.0 0.0 0.0 (
189 1 12000.0 12000.0 0.0 lts_query.c.ai_diagnosis_result == 2,
190 1 0.0 0.0 0.0 "WARNING",
191 ),
192 1 0.0 0.0 0.0 (
193 1 11000.0 11000.0 0.0 lts_query.c.ai_diagnosis_result == 3,
194 1 1000.0 1000.0 0.0 "CRITICAL",
195 ),
196 1 0.0 0.0 0.0 (
197 1 11000.0 11000.0 0.0 lts_query.c.ai_diagnosis_result == 4,
198 1 1000.0 1000.0 0.0 "FAULT",
199 ),
200 ]
201 1 0.0 0.0 0.0 ).label("asset_state"),
202 )
203 1 0.0 0.0 0.0 .select_from(Asset)
204 .join(
205 1 0.0 0.0 0.0 Site,
206 1 20000.0 20000.0 0.0 and_(
207 1 21000.0 21000.0 0.0 Asset.site_id == Site.id,
208 1 16000.0 16000.0 0.0 Asset.company_id == company_id,
209 ),
210 )
211 .join(
212 1 0.0 0.0 0.0 lts_query,
213 1 10000.0 10000.0 0.0 Asset.id == lts_query.c.asset_id,
214 )
215 .join(
216 1 0.0 0.0 0.0 prev_query,
217 1 11000.0 11000.0 0.0 Asset.id == prev_query.c.asset_id,
218 )
219 1 0.0 0.0 0.0 .order_by(Asset.id)
220 .all()
221 )
222
223 1 1000.0 1000.0 0.0 responses = []
224 3507 1123000.0 320.2 0.1 for data in main_query:
225 3507 6683000.0 1905.6 0.4 obj = data._asdict()
226 3507 3677000.0 1048.5 0.2 obj = key_mapping.voltage(obj)
227 3507 2206000.0 629.0 0.1 obj = key_mapping.capacity(obj)
228
229 3507 1356000.0 386.7 0.1 responses.append(obj)
Python
복사
line-profiler에 소요된 총 시간은 1.81674초였습니다.
View table 생성
*필요에 따라서 각 회사별 View 테이블을 만들어서 필요할 시점에 해당 테이블을 불러와 사용할 수 있을것으로 보입니다.
CREATE VIEW temp_view_company_16 AS (
-- [설비별 최신 계측날짜, 직전 계측날짜]
WITH acq_date_by_asset AS (
SELECT a.asset_id, MAX(a.acquisition_date) AS acquisition_date,
CASE WHEN MAX(a.prev_acquisition_date) IS NULL THEN MAX(a.acquisition_date)
ELSE MAX(a.prev_acquisition_date) END
AS prev_acquisition_date
FROM (
SELECT a.id AS asset_id,
a.asset_name ,
dmbd.acquisition_date ,
LEAD(dmbd.acquisition_date, 1)
OVER (PARTITION BY a.id, a.asset_name ORDER BY dmbd.acquisition_date DESC)
AS prev_acquisition_date
FROM substation.asset a LEFT JOIN substation.data_mtr_body_dga dmbd
ON a.id = dmbd.asset_id
WHERE a.company_id = 16
ORDER BY a.id, a.asset_name ,dmbd.acquisition_date DESC
) a
GROUP BY a.asset_id
),
-- [설비별 AI 프로세스 진행 여부]
ai_process_state AS (
SELECT aps.asset_id ,'RUNNING' AS ai_process
FROM substation.ai_process_status aps
WHERE is_ai_process_finish IS NULL
ORDER BY aps.asset_id
),
-- [설비 DGA 계측 날짜별 AI 연산 결과]
diag_info AS (
SELECT dmbd.asset_id , dmbd.acquisition_date , ambd.ai_diagnosis_result
FROM substation.data_mtr_body_dga dmbd LEFT JOIN substation.ai_mtr_body_dga ambd
ON dmbd.id = ambd.data_mtr_body_dga_id
)
SELECT a.id as asset_id, a.asset_name, s.id AS site_id, s.site_name
, a.voltage_low, a.voltage_high, a.capacity_low, a.capacity_high, a.manufacturer
, TO_CHAR(a.manufacturing_date,'YYYY-MM-DD') AS manufacturing_date
, TO_CHAR(a.operating_date,'YYYY-MM-DD') AS operating_date
, a.USAGE, a.resource_id, a.serial_no
, lts_query.acquisition_date
, CASE WHEN lts_query.ai_process = 'RUNNING' THEN 'UNKNOWN'
WHEN lts_query.ai_diagnosis_result = 0 THEN 'NORMAL'
WHEN lts_query.ai_diagnosis_result = 1 THEN 'CAUTION'
WHEN lts_query.ai_diagnosis_result = 2 THEN 'WARNING'
WHEN lts_query.ai_diagnosis_result = 3 THEN 'CRITICAL'
WHEN lts_query.ai_diagnosis_result = 4 THEN 'FAULT'
END AS asset_state
, CASE WHEN lts_query.ai_diagnosis_result <> prev_query.ai_diagnosis_result THEN TRUE
ELSE FALSE END
AS is_state_changed
FROM substation.asset a ,
substation.site s ,(
SELECT a.asset_id, b.ai_diagnosis_result, a.acquisition_date, aps.ai_process
FROM acq_date_by_asset a INNER JOIN diag_info b
ON a.asset_id = b.asset_id LEFT JOIN ai_process_state aps
ON a.asset_id = aps.asset_id
WHERE a.acquisition_date = b.acquisition_date
) lts_query,
(
SELECT a.asset_id, b.ai_diagnosis_result ,a.acquisition_date
FROM acq_date_by_asset a INNER JOIN diag_info b
ON a.asset_id = b.asset_id
WHERE a.prev_acquisition_date = b.acquisition_date
) prev_query
WHERE a.site_id = s.id
AND a.company_id = 16
AND a.id = lts_query.asset_id
AND a.id = prev_query.asset_id
ORDER BY a.id
)
Python
복사
View entity 생성
class TempViewCompany16(Base):
__tablename__ = "temp_view_company_16"
__table_args__ = {"schema": "substation"}
# Columns
asset_id = Column("asset_id", Integer, primary_key=True)
asset_name = Column("asset_name", String)
site_id = Column("site_id", Integer)
site_name = Column("site_name", String)
voltage_low = Column("voltage_low", Numeric())
voltage_high = Column("voltage_high", Numeric())
capacity_low = Column("capacity_low", Numeric())
capacity_high = Column("capacity_high", Numeric())
manufacturer = Column("manufacturer", String)
manufacturing_date = Column("manufacturing_date", DateTime(timezone=True))
operating_date = Column("operating_date", DateTime(timezone=True))
usage = Column("usage", String)
resource_id = Column("resource_id", String)
serial_no = Column("serial_no", String)
acquisition_date = Column("acquisition_date", DateTime(timezone=True))
asset_state = Column("asset_state", String)
is_state_changed = Column("is_state_changed", Boolean)
Python
복사
After (View ORM)
Total time: 1.47011 s
File: line_profiler_test_copy.py
Function: test_func at line 31
Line # Hits Time Per Hit % Time Line Contents
==============================================================
31 def test_func():
32 1 13000.0 13000.0 0.0 Session = sessionmaker(bind=engine)
33 1 130000.0 130000.0 0.0 session = Session()
34 1 0.0 0.0 0.0 company_id = 16
35
36 1 1000.0 1000.0 0.0 start = time.time()
37 1 156199000.0 156199000.0 10.6 math.factorial(100000)
38
39 1 1302447000.0 1302447000.0 88.6 results = session.query(
40 1 10000.0 10000.0 0.0 TempViewCompany16.asset_id,
41 1 0.0 0.0 0.0 TempViewCompany16.asset_name,
42 1 1000.0 1000.0 0.0 TempViewCompany16.site_id,
43 1 1000.0 1000.0 0.0 TempViewCompany16.site_name,
44 1 1000.0 1000.0 0.0 TempViewCompany16.voltage_low,
45 1 1000.0 1000.0 0.0 TempViewCompany16.voltage_high,
46 1 0.0 0.0 0.0 TempViewCompany16.capacity_low,
47 1 0.0 0.0 0.0 TempViewCompany16.capacity_high,
48 1 1000.0 1000.0 0.0 TempViewCompany16.manufacturer,
49 1 1000.0 1000.0 0.0 TempViewCompany16.manufacturing_date,
50 1 0.0 0.0 0.0 TempViewCompany16.operating_date,
51 1 0.0 0.0 0.0 TempViewCompany16.usage,
52 1 0.0 0.0 0.0 TempViewCompany16.resource_id,
53 1 1000.0 1000.0 0.0 TempViewCompany16.serial_no,
54 1 0.0 0.0 0.0 TempViewCompany16.acquisition_date,
55 1 0.0 0.0 0.0 TempViewCompany16.asset_state,
56 1 1000.0 1000.0 0.0 TempViewCompany16.is_state_changed,
57 ).all()
58
59 1 0.0 0.0 0.0 responses = []
60 3507 556000.0 158.5 0.0 for data in results:
61 3507 5282000.0 1506.1 0.4 obj = data._asdict()
62 3507 3085000.0 879.7 0.2 obj = key_mapping.voltage(obj)
63 3507 1493000.0 425.7 0.1 obj = key_mapping.capacity(obj)
64
65 3507 830000.0 236.7 0.1 responses.append(obj)
66
67 1 2000.0 2000.0 0.0 end = time.time()
68 1 40000.0 40000.0 0.0 print("****************************************************")
69 1 10000.0 10000.0 0.0 print(f"{end - start:.5f} sec")
70 1 2000.0 2000.0 0.0 print("****ls************************************************")
71 1 0.0 0.0 0.0 return responses
Python
복사
line-profiler에 소요된 총 시간은 1.47011초였습니다.
결과적으로 기존 ORM Join 으로 만들어진 SQL 을 View 테이블로 만들어서 사용해 비교했을 경우 1.81674초에서 1.47011초로 약 0.4 초 단축 (20%) 정도의 성능 향상을 이뤄냈습니다.
또한 View 테이블을 사용할 경우 DB 의 성능에 좀 더 영향을 받을 것으로 보이며, 테스트로 사용 했었던 local DB 가 아닌 고 성능의 DB 를 사용했다면 더 성능 향상이 좋아질 것으로 보입니다.
참고로 Raw SQL 로 측정할 경우 1.05664초로 각각 0.8, 0.4 초의 성능 차이를 보여줬습니다.
정리하자면 ORM 을 잘 사용한다면, Raw SQL 과 비슷한 정도로 구현이 가능할 것으로 보입니다.
하지만 잘 사용하기 위해서는 기본적으로 SQL 에 대해서, 그리고 SQL 튜닝 관점에서의 지식이 밑바탕이 되어야 할 것으로 보입니다.
3. ORM의 특장점
SQL 과 ORM 에 대해서 파고들고, 각 진영의 토론 배틀을 깊숙이 지켜본 사람으로서, ORM 만이 가지고 있는 특장점이 존재합니다. C#, Java, Python 등 객체지향 언어를 사용해서 애플리케이션을 개발 하게 된다면, 객체지향 설계 원칙을 따르게 되지만, RDBMS 는 이러한 객체지향 구조로 맞물려 개발하기에 어려움이 있습니다.
예를 들어 INSERT의 경우, ORM 은 필요한 클래스에 필드를 추가하면 해당 테이블에 필드가 자동으로 추가되지만, Raw SQL 을 사용하는 경우에는 해당 테이블을 사용하는 모든 SQL 을 수정해야 합니다. Legacy 코드가 많을 수록 이 작업은 번거로워 질 뿐만 아니라, 객체지향적 개발에서 멀어질 수 있습니다.
또한 아래 같은 경우에서는 ORM 이 더 막강한 성능을 낼 수 있습니다.
A 라는 객체는 B, C, D, E와 연관되어 있고,
B 와 C 는 필수적으로 가져와야 하지만,
D, E는 선택적으로 가져와야 하는 상황 일 경우
•
ORM 을 사용하는 경우
◦
ORM 을 사용하면 A 객체를 로드할 때 B 와 C 를 가져오는 쿼리를 실행합니다. 이때 B 와 C 의 정보가 필요한 경우 쿼리를 실행하여 가져옵니다.
◦
A 객체를 사용하는 코드에서 D 나 E 에 접근이 필요한 경우, ORM 은 필요한 쿼리를 추가적으로 실행하여 D와 E 의 정보를 가져옵니다. 이는 객체 그래프를 탐색하여 필요한 정보를 동적으로 가져올 수 있게 해줍니다.
•
Raw SQL 을 사용하는 경우
◦
SQL 을 사용하여 B 와 C 를 가져오는 쿼리를 실행합니다. A 객체를 생성할 때, B 와 C 의 정보를 가져와서 A 객체에 매핑합니다
◦
D나 E 에 접근이 필요한 경우, 추가적인 SQL 쿼리를 실행하여 D와 E 의 정보를 가져옵니다. 이를 위해 A 객체를 생성할 때 사용한 쿼리와 별도의 쿼리를 실행해야 합니다.
◦
이렇게 되면 처음부터 B,C,D,E 를 모두 가져오는 것은 비효율적입니다. 필요한 정보를 가져오기 위해 여러번의 쿼리를 실행해야 하므로 성능 저하와 불필요한 데이터 로딩이 발생합니다.
마치며…
이전 포스팅 글과 이번 글을 함께 보신 분이라면, 각각 SQL과 ORM의 관점에서 쓴 글처럼 보일 수 있을 것 같습니다.
SW 엔지니어는 결국 마주하는 이슈를 해결해 나가는 사람들이고, 이러한 이슈를 해결해 나가기 위해서 도구에 종속적인 것보다는 문제를 해결해 나가는 것에 더 초점을 맞춰야 한다고 생각합니다. 이러한 측면에서 본다면 사실 SQL이나 ORM 같은 특정 도구에 치우치기보다는 현재 상황에 맞게 최적의 선택을 하는 것이 더 중요한 것 같습니다.
다만 ‘도메인 주도 설계(DDD)’나 ‘마이크로 서비스 아키텍처(MSA)’ 가 트렌드가 됨에 따라서, 트렌디한 개발 환경을 가진 곳인 경우, 기존의 모놀리식 시스템에서 분리해, 서비스마다 독자적인 DB를 갖거나, NoSql 같은 관계형 DB에서 벗어난 아키텍처를 채택하고 있습니다.
이러한 방향은 모놀리식 구조에 비해 SQL 조인 복잡성이 줄어들게 되어 ORM으로 충분히 성능을 챙길 수 있는 환경이 만들어지게 되고, ORM을 사용하면 기존 SQL 이 가지고 있는 수많은 Mapping 이슈도 해결이 될 수 있는 순방향 Cycle 이 형성될 수 있다고 생각합니다.
하지만 한편으론 제조 대기업에서 일하면서 이미 이러한 방법을 알고 있는 실력 있는 ‘개발자’나 ‘아키텍처’가 많았을 텐데, 왜 그 사람들이 모여서 결국 거대한 모놀리식 아키텍처를 선택했을 까? 를 다시금 생각해보면, 세상에 만능 '치트키’ 는 없듯이 풀어나가야하는 이슈마다 최적의 선택이 다르지 않을까 싶습니다.
이 글을 쓴 사람

제조 분야 대기업에서 수많은 설비 데이터를 가공하고 운영해왔습니다.
CTO (Chief Technology Officer)를 꿈꾸며 마주하는 이슈를 풀어가기 위해 아키텍처와 컨셉을 고민하고, 이런 노력이 제품에 반영될 수 있는 환경을 찾아 스타트업인 원프레딕트에 합류하게 되었습니다.
장진수님이 쓴 또 다른 글 보러가기
원프레딕트 홈페이지
https://onepredict.ai/
원프레딕트 블로그
https://blog.onepredict.ai/
원프레딕트 기술 블로그
https://tech.onepredict.ai