MES, ERP처럼 대규모 산업 현장에 디지털 전환을 가져다주는 솔루션의 백엔드 작업을 하다보면, 데이터베이스에 쌓인 여러 데이터를 활용해서 원하는 형태로 데이터를 가져올 수 있어야 하는 역량이 중요합니다. 뿐만 아니라 부하가 큰 트랜잭션 쿼리를 날리다 보니, DA (Data Analyst)를 통해서 쿼리를 튜닝하는 일도 빈번한데요.
이번 포스트에서는 Raw SQL과 ORM을 통해 데이터베이스에서 원하는 정보의 데이터를 가져오는 성능을 비교해보려 합니다.
1. ORM vs SQL
기존 데이터베이스에서 원하는 데이터를 가져오려면, 프로그램이 종료되어도 데이터가 ‘영속적으로’ 남아있어야 합니다. 앞서 언급한 SQL과 ORM은 이 데이터 영속성을 갖추기 위한 프레임워크 중 하나입니다.
•
SQL은 Structured Query Language의 약자로, 관계형 데이터베이스를 관리, 분석, 조작하는 데 사용되는 프로그래밍 언어입니다.
•
ORM은 Object-Relation Mapping의 약자로, 객체(object)와 데이터베이스 테이블을 매핑하여 데이터를 객체화하는 기술입니다.
언제부터인가 ORM이 트렌드가 되고, 누구나 다 SQL보다는 ORM으로 데이터베이스 트랜잭션을 처리하기 원하지만 구체적으로 어떤 장점이 있기에 ORM을 사용하고 싶은가 라는 질문에는 여러 개발자, 친구, 선배에게 물어봐도 그럴듯한 답변을 듣지 못해 혼자서 많은 고민을 해왔습니다.
그나마 아래와 같이 ‘DB의 종류에 구애받지 않기에', ‘개발 생산성을 높일 수 있어서’ 등의 답변을 들었지만 개인적으로는 저를 설득할 만한 대답은 되지 못했습니다.
ORM에 대한 의문점
•
DB의 종류에 구애받지 않는다?
운영중인 시스템의 DB를 다른 DB로 마이그레이션 한다는 것은 엄청난 비용이 드는 행위입니다. 이전 직장의 경우, 거대한 Oracle DB를 중심으로 여러 시스템이 DB를 물어 운용되는 형태에서, Oracle Version을 업데이트 하는 행위도, ‘데이터 정합성', ‘SQL 문법 변화’ 등 며칠에 걸쳐 많은 인력이 붙어 진행됐었습니다.
•
개발 생산성을 높일 수 있다?
규모가 작은 초기 시스템에서는 ERD를 작성할 필요가 없기에 개발 생산성을 높일 수 있다는 점에 공감하지만, 규모가 커진 상태에서는 개발 생산성 효과가 오히려 떨어지는 것 아닌가 하는 의문이 있습니다. 수십~ 수백개의 테이블로 구성된 DB 구조를 ERD 가 아닌 수천 줄짜리 코드를 보고 테이블 관계를 이해할 수 있나라는 의문점이 듭니다.
•
가독성을 높일 수 있다?
프로그래밍 언어로 만든 함수는 ‘논리’가 생명이지만, DB를 다루는 SQL 은 ‘데이터 정합성’이 생명입니다. 똑같은 SQL 도 개발DB, 운영DB 그리고 시간에 따라 데이터가 다르게 조회됩니다. 아래 본문처럼, ORM 은 SQL 블록단위로 코드를 작성한 구조가 얼핏 보면 가독성이 좋아보일 수 있으나, 블록 단위 데이터를 까볼 수는 없습니다. 반대로 Raw SQL 은 거대한 SQL 구조에서 내부 블록단위로 실행해 데이터를 확인해 볼 수 있고, 어떻게 수정해야 할지 바로 확인이 가능합니다.
•
성능을 높일 수 있다?
기본적으로 ORM으로 데이터를 처리하는게 SQL을 활용하는 것보다 성능이 월등히 떨어집니다. (ORM 내부적으로 SQL 로 변환하는 과정을 거치며, 조인이 많아질 수록 성능은 기하급수적으로 감소합니다) 또한 튜닝이 필요한 시점에는 결국 다시 SQL로 작성해야 하는 단점이 있습니다.
하지만 최근 지하철을 타며 회사를 출근하다가 문득 이 논쟁에 대한 정답을 찾았습니다.
그것은 바로 OLTP 와 OLAP 서비스에 따라 다르다는 것!
2. OLTP와 OLAP
이 용어는 데이터베이스에 대해서 공부해본 사람이라면 한 번쯤 들어봤을 것으로 예상됩니다.
OLTP (Online Transaction Processing)는 현재의 데이터 처리가 얼마나 정확하고, 무결한지가 중요합니다. 그렇기 때문에 주로 데이터의 저장, 삭제, 수정 등의 실질적인 데이터 수정하는 작업을 의미하고, 단순 CRUD가 많고 트래픽이 방대한 서비스에서 주로 사용됩니다.
OLAP (Online Analytical Processing)는 이미 저장된 데이터를 바탕으로 어떤 정보를 제공하는지가 중요합니다. 따라서 OLAP 는 데이터가 무결하고 정확하다는 전재를 바탕으로 고객 또는 사용자가 원하는 정보를 어떤식으로 표현하고 제공하는지를 의미하는 용어입니다.
구분 | OLTP | OLAP |
목적 | 비즈니스 활동 지원 | 비즈니스 활동에 대한 평가 및 분석 |
주 트랜잭션 형태 | SELECT, INSERT, UPDATE, DELETE | SELECT |
속도 | 수 초 이내 | 수 초 이상 ~ 수 분 이내 |
관리 단위 | 테이블 | 분석된 정보 |
최적화 방법 | 트랜잭션 효율화, 무결성의 극대화 | 조회 속도, 정보의 가치, 편의성 |
데이터 특성 | 트랜잭션 중심 | 정보 중심 |
예시 | - 회원정보 수정
- 상품 주문
- 댓글 남기기 및 수정 | - 1년간의 주요 인기 트렌드
- 한달간의 항목별 수입 및 지출
- 10년간 A회사의 직급별 임금 상승률 |
정리를 하자면, 단순한 데이터의 조회가 많고 트래픽이 많은 B2C 서비스의 경우에는 ORM 이 트렌드가 되고, 데이터를 가공하고 분석해야 하는 B2B 시스템(제조, 금융)에서는 SQL 이 많이 쓰이는 것으로 보입니다.
정리를 하자면 단순한 데이터의 조회 및 저장이 주로 발생하는, 가볍지만 트래픽 건수가 많은 B2C 서비스의 경우에는 ORM 이 트렌드가 되고, 데이터를 가공하고 분석하는, 무겁지만 트래픽 건수가 적은 서비스인 B2B 시스템(제조, 금융) 에서는 SQL 이 많이 쓰이는 것으로 보입니다.
좀 더 나가면 DDD (도메인 주도 설계) 관점에서는 OLTP 시스템이 OLAP 시스템보다 좀 더 적합해 보일 수 있을 것 같습니다.
*도메인 주도 설계에서 도메인 객체를 잘 정의한다면, 복잡한 쿼리를 하지 않도록 구현이 가능합니다.
3. 수정 API
companies/{company_id}/enterprise-mtr-grade-status
변압기의 DGA 가스를 측정해서 AI 알고리즘을 돌린 후, 최신 진단한 상태값과 바로 직전 진단한 DGA의 상태값을 보내, 설비 별 상태값의 추이를 보여주도록 하는 API 입니다
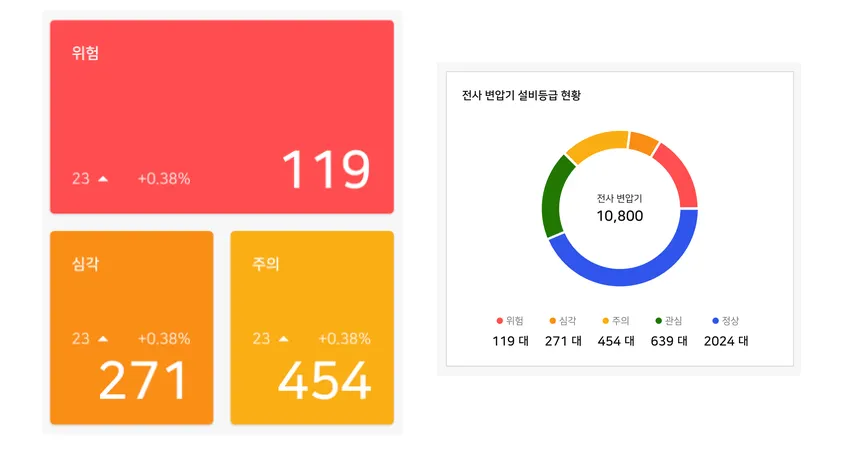
서브스테이션 2.0 대시보드 화면
4. DB 구조
해당 시스템에서는 PostgreSQL DB를 사용했으며, 설비를 지칭하는 Asset 테이블과, DGA 가스를 측정한 DataMtrBodyDg 그리고 설비와, DGA 정보를 활용해 AI 알고리즘을 돌린 AiMtrBodyDga 테이블을 이용하여 데이터를 가져옵니다. (구체적인 테이블 설명과 칼럼 타입, 결과값은 보안상 생략합니다.)
Before (ORM)
해당 방식은 SqlAlchemy의 ORM을 활용해서 데이터를 가져오는 형태의 데이터 입니다.
# time 측정
start = time.time()
math.factorial(100000)
# asset 별 모든 측정일과 이전 측정일 추출
asset_info = (
session.query(
Asset.id.label("asset_id"),
Asset.asset_name.label("asset_name"),
DataMtrBodyDga.acquisition_date.label("acquisition_date"),
func.lead(DataMtrBodyDga.acquisition_date, 1)
.over(
partition_by=[Asset.id, Asset.asset_name],
order_by=DataMtrBodyDga.acquisition_date.desc(),
)
.label("prev_acquisition_date"),
)
.select_from(Asset)
.join(DataMtrBodyDga, DataMtrBodyDga.asset_id == Asset.id)
.filter(
Asset.company_id == company_id,
Asset.asset_type == "MTR",
Asset.serial_no.in_(available_licenses),
)
.order_by(
Asset.id, Asset.asset_name, DataMtrBodyDga.acquisition_date.desc()
)
.subquery()
)
# DataMtrBodyDga 테이블 기준 asset 별 최신 측정일과 바로 이전 측정일 추출
asset_acquisition_info = (
session.query(
asset_info.c.asset_id,
asset_info.c.asset_name,
func.max(asset_info.c.acquisition_date).label("acquisition_date"),
case(
[
(
func.max(asset_info.c.prev_acquisition_date) == None,
func.max(asset_info.c.acquisition_date),
),
(
func.max(asset_info.c.prev_acquisition_date) != None,
func.max(asset_info.c.prev_acquisition_date),
),
]
).label("prev_acquisition_date"),
)
.select_from(asset_info)
.group_by(asset_info.c.asset_id, asset_info.c.asset_name)
.subquery()
)
# asset 측정일 기준별 진단 결과 건수 추출
diag_info = (
session.query(
DataMtrBodyDga.asset_id.label("asset_id"),
DataMtrBodyDga.acquisition_date.label("acquisition_date"),
AiMtrBodyDga.ai_diagnosis_result.label("ai_diagnosis_result"),
)
.select_from(DataMtrBodyDga) # LEFT OUTER JOIN 의 기준 테이블을 설정하기 위해 사용
.outerjoin(Asset, DataMtrBodyDga.asset_id == Asset.id)
.outerjoin(
AiMtrBodyDga,
DataMtrBodyDga.id == AiMtrBodyDga.data_mtr_body_dga_id,
)
.filter(
Asset.company_id == company_id,
Asset.asset_type == "MTR",
Asset.serial_no.in_(available_licenses),
)
.subquery()
)
# asset 별 최신 측정일 기준 상태 건수
query1 = (
session.query(
func.count(diag_info.c.ai_diagnosis_result).label("total_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 0, "NORMAL")])
).label("normal_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 1, "CAUTION")])
).label("caution_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 2, "WARNING")])
).label("warning_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 3, "CRITICAL")])
).label("critical_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 4, "FAULT")])
).label("fault_cnt"),
)
.select_from(asset_acquisition_info) # LEFT OUTER JOIN 의 기준 테이블을 설정하기 위해 사용
.join(
diag_info,
and_(
asset_acquisition_info.c.asset_id == diag_info.c.asset_id,
asset_acquisition_info.c.acquisition_date
== diag_info.c.acquisition_date,
),
)
.first()
)
# asset 별 이전 측정일 기준 상태 건수
query2 = (
session.query(
func.count(diag_info.c.ai_diagnosis_result).label("total_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 0, "NORMAL")])
).label("normal_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 1, "CAUTION")])
).label("caution_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 2, "WARNING")])
).label("warning_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 3, "CRITICAL")])
).label("critical_cnt"),
func.count(
case([(diag_info.c.ai_diagnosis_result == 4, "FAULT")])
).label("fault_cnt"),
)
.select_from(asset_acquisition_info) # LEFT OUTER JOIN 의 기준 테이블을 설정하기 위해 사용
.join(
diag_info,
and_(
asset_acquisition_info.c.asset_id == diag_info.c.asset_id,
asset_acquisition_info.c.prev_acquisition_date
== diag_info.c.acquisition_date,
),
)
.first()
)
end = time.time()
print("****************************************************")
print(f"{end - start:.5f} sec")
print("****************************************************")
responses = {"current": query1._asdict(), "prev": query2._asdict()}
SQL
복사
결과
1회시도 (DB Cache 제거) | 2회 (DB Cache 제거) | 3회 (DB Cache 제거) | |
1 try | 6.62579 sec | 6.28475 sec | 6.25671 sec |
2 try | 5.42588 sec | 5.30851 sec | 4.69481 sec |
3 try | 4.86993 sec | 4.90473 sec | 4.73450 sec |
After (SQL)
해당 방식은 SqlAlchemy 의 Core 를 활용해서 Raw SQL 형태로 데이터를 가져오는 데이터 입니다.
기존 ‘IN’ 절로 처리한 부분을, ‘ANY’ 로 사용한 이유는, PostgreSQL 에서 varchar 타입의 칼럼의 경우 , SqlAlchemy 는 Record 로 인지하고 값을 비교하여 에러가 납니다. 해당 에러에 대해서 아래와 같이 변환하여 사용합니다.
ANY (select unnest(:available_licenses))
# time 측정
start = time.time()
math.factorial(100000)
sql_statement = text(
"""
WITH asset_info AS (
SELECT a.asset_id, a.asset_name
,MAX(a.acquisition_date) AS acquisition_date
,CASE WHEN MAX(a.prev_acquisition_date) IS NULL THEN MAX(a.acquisition_date)
WHEN MAX(a.prev_acquisition_date) IS NOT NULL THEN MAX(a.prev_acquisition_date)
END AS prev_acquisition_date
FROM (
SELECT a.id AS asset_id
,a.asset_name AS asset_name
,dmbd.acquisition_date
,LEAD(dmbd.acquisition_date,1)
OVER (PARTITION BY a.id, a.asset_name ORDER BY dmbd.acquisition_date DESC )
AS prev_acquisition_date
FROM substation.asset a INNER JOIN substation.data_mtr_body_dga dmbd
ON a.id = dmbd.asset_id
WHERE a.asset_type = 'MTR'
AND a.company_id = :company_id
AND a.serial_no = ANY (SELECT UNNEST(:available_licenses))
ORDER BY a.id, a.asset_name, dmbd.acquisition_date DESC
) a
GROUP BY a.asset_id, a.asset_name
), diag_info AS (
SELECT dmbd.asset_id, dmbd.acquisition_date , ambd.ai_diagnosis_result
FROM substation.data_mtr_body_dga dmbd LEFT OUTER JOIN substation.asset a
ON dmbd.asset_id = a.id LEFT OUTER JOIN substation.ai_mtr_body_dga ambd
ON dmbd.id = ambd.data_mtr_body_dga_id
WHERE a.company_id = :company_id
AND a.serial_no = ANY (SELECT UNNEST(:available_licenses))
AND a.asset_type = 'MTR'
)
SELECT COUNT(*) AS TOTAL_CNT
,COUNT(CASE WHEN b.ai_diagnosis_result = 0 THEN 'NORMAL' END ) AS NORMAL
,COUNT(CASE WHEN b.ai_diagnosis_result = 1 THEN 'CAUTION' END ) AS CAUTION
,COUNT(CASE WHEN b.ai_diagnosis_result = 2 THEN 'WARNING' END ) AS WARNING
,COUNT(CASE WHEN b.ai_diagnosis_result = 3 THEN 'CRITICAL' END ) AS CRITICAL
,COUNT(CASE WHEN b.ai_diagnosis_result = 4 THEN 'FAULT' END ) AS FAULT
FROM asset_info a LEFT OUTER JOIN diag_info b
ON a.asset_id = b.asset_id
WHERE a.acquisition_date = b.acquisition_date
UNION ALL
SELECT COUNT(*) AS TOTAL_CNT
,COUNT(CASE WHEN b.ai_diagnosis_result = 0 THEN 'NORMAL' END ) AS NORMAL
,COUNT(CASE WHEN b.ai_diagnosis_result = 1 THEN 'CAUTION' END ) AS CAUTION
,COUNT(CASE WHEN b.ai_diagnosis_result = 2 THEN 'WARNING' END ) AS WARNING
,COUNT(CASE WHEN b.ai_diagnosis_result = 3 THEN 'CRITICAL' END ) AS CRITICAL
,COUNT(CASE WHEN b.ai_diagnosis_result = 4 THEN 'FAULT' END ) AS FAULT
FROM asset_info a LEFT OUTER JOIN diag_info b
ON a.asset_id = b.asset_id
WHERE a.prev_acquisition_date = b.acquisition_date
"""
)
result = session.execute(sql_statement,{
"available_licenses": available_licenses,
"company_id": company_id
})
results = [rowproxy._mapping for rowproxy in sql_result]
end = time.time()
print("****************************************************")
print(f"{end - start:.5f} sec")
print("****************************************************")
responses = {"current": results[0], "prev": results[1]}
SQL
복사
결과
1회시도 (DB Cache 제거) | 2회 (DB Cache 제거) | 3회 (DB Cache 제거) | |
1 try | 4.37999 sec | 4.64817 sec | 4.29508 sec |
2 try | 1.76666 sec | 1.64863 sec | 1.59068 sec |
3 try | 1.61587 sec | 1.56709 sec | 1.59817 sec |
정리하자면, SQL 의 처리 과정이나, 로직에 대해서는 따로 설명하지는 않지만, DB 캐시에 의한 성능 효과를 고려해서 1try 기준의 평균값으로 시간을 측정했을 때 Before(ORM) 6.38908, After(SQL) 4.44108 아래와 같이 구해집니다.
정리하자면 해당 케이스의 경우에는 기존 약 6.38초에서 4.44초로 기존 대비 69%의 시간 단축을 가져왔습니다.
(4.44108 / 6.38908 ) x 100 = 69.51 %
소요 시간을 기존 대비 30.48% 가량 줄일 수 있었습니다.
다만 흥미로운 부분으로 DB 캐시 효과를 고려한 3try 기준의 평균값으로 측정하면 아래와 같이 구해집니다. (Before(ORM) 4.83638, After(SQL) 1.59371)
(1.59371 / 4.83638 ) x 100 = 32.95 %
소요 시간을 기존 대비 67% 가량 줄일 수 있었습니다.
이 수치는, 개발환경에서 진행된 테스트로, 테이블에 적재된 데이터 용량과 , DB 부하상태에 따라서 수치에 영향을 받을 수 있으며, 그럴 경우 성능은 더 차이가 날 것으로 보입니다.
*DB 조인이 더 많아지는 경우에도 마찬가지 입니다.
5. 성능 저하의 원인
그렇다면 ‘ORM이 변경한 쿼리 구조가 성능이 나쁜건지’ 혹은 ‘ORM 이 SQL 로 변경하는 과정에서 오랜걸린 건지’에 대한 궁금중이 생길 수 있을 것 같은데요. ORM이 변경한 쿼리로 직접 실행 했을 때의 결과는 아래와 같았습니다.
ORM 으로 변환된 SQL
start = time.time()
math.factorial(100000)
session = DatabaseFactory.create_session()
try:
company_name = (
session.query(Company.company_name)
.filter(Company.id == company_id)
.first()
.company_name
)
available_licenses = LicenseUtils.license_check_all(company_name=company_name)
query_1 = text(
"""
SELECT count(anon_1.ai_diagnosis_result) AS total_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 0) THEN 'NORMAL' END) AS normal_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 1) THEN 'CAUTION' END) AS caution_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 2) THEN 'WARNING' END) AS warning_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 3) THEN 'CRITICAL' END) AS critical_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 4) THEN 'FAULT' END) AS fault_cnt
FROM (
SELECT anon_3.asset_id AS asset_id
, anon_3.asset_name AS asset_name
, MAX(anon_3.acquisition_date) AS acquisition_date
, CASE WHEN (MAX(anon_3.prev_acquisition_date) IS NULL) THEN MAX(anon_3.acquisition_date)
WHEN (MAX(anon_3.prev_acquisition_date) IS NOT NULL) THEN MAX(anon_3.prev_acquisition_date)
END AS prev_acquisition_date
FROM (
SELECT substation.asset.id AS asset_id
, substation.asset.asset_name AS asset_name
, substation.data_mtr_body_dga.acquisition_date AS acquisition_date
, LEAD(substation.data_mtr_body_dga.acquisition_date, 1)
OVER (PARTITION BY substation.asset.id, substation.asset.asset_name
ORDER BY substation.data_mtr_body_dga.acquisition_date DESC
) AS prev_acquisition_date
FROM substation.asset JOIN substation.data_mtr_body_dga
ON substation.data_mtr_body_dga.asset_id = substation.asset.id
WHERE substation.asset.company_id = :company_id
AND substation.asset.asset_type = 'MTR'
AND substation.asset.serial_no = ANY (SELECT UNNEST(:available_licenses))
ORDER BY substation.asset.id, substation.asset.asset_name, substation.data_mtr_body_dga.acquisition_date DESC
) AS anon_3
GROUP BY anon_3.asset_id, anon_3.asset_name) AS anon_2 JOIN
(
SELECT substation.data_mtr_body_dga.asset_id AS asset_id
, substation.data_mtr_body_dga.acquisition_date AS acquisition_date
, substation.ai_mtr_body_dga.ai_diagnosis_result AS ai_diagnosis_result
FROM substation.data_mtr_body_dga LEFT OUTER JOIN substation.asset
ON substation.data_mtr_body_dga.asset_id = substation.asset.id
LEFT OUTER JOIN substation.ai_mtr_body_dga
ON substation.data_mtr_body_dga.id = substation.ai_mtr_body_dga.data_mtr_body_dga_id
WHERE substation.asset.company_id = :company_id
AND substation.asset.asset_type = 'MTR'
AND substation.asset.serial_no = ANY (SELECT UNNEST(:available_licenses))
) AS anon_1
ON anon_2.asset_id = anon_1.asset_id
AND anon_1.acquisition_date = anon_2.acquisition_date
LIMIT 1
"""
)
sql_result1 = session.execute(
query_1,
{
"available_licenses": available_licenses,
"company_id": company_id,
},
)
query_2 = text(
"""
SELECT count(anon_1.ai_diagnosis_result) AS total_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 0) THEN 'NORMAL' END) AS normal_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 1) THEN 'CAUTION' END) AS caution_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 2) THEN 'WARNING' END) AS warning_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 3) THEN 'CRITICAL' END) AS critical_cnt
, count(CASE WHEN (anon_1.ai_diagnosis_result = 4) THEN 'FAULT' END) AS fault_cnt
FROM (
SELECT anon_3.asset_id AS asset_id
, anon_3.asset_name AS asset_name
, MAX(anon_3.acquisition_date) AS acquisition_date
, CASE WHEN (MAX(anon_3.prev_acquisition_date) IS NULL) THEN MAX(anon_3.acquisition_date)
WHEN (MAX(anon_3.prev_acquisition_date) IS NOT NULL) THEN MAX(anon_3.prev_acquisition_date)
END AS prev_acquisition_date
FROM (
SELECT substation.asset.id AS asset_id
, substation.asset.asset_name AS asset_name
, substation.data_mtr_body_dga.acquisition_date AS acquisition_date
, LEAD(substation.data_mtr_body_dga.acquisition_date, 1)
OVER (PARTITION BY substation.asset.id, substation.asset.asset_name
ORDER BY substation.data_mtr_body_dga.acquisition_date DESC
) AS prev_acquisition_date
FROM substation.asset JOIN substation.data_mtr_body_dga
ON substation.data_mtr_body_dga.asset_id = substation.asset.id
WHERE substation.asset.company_id = :company_id
AND substation.asset.asset_type = 'MTR'
AND substation.asset.serial_no = ANY (SELECT UNNEST(:available_licenses))
ORDER BY substation.asset.id, substation.asset.asset_name, substation.data_mtr_body_dga.acquisition_date DESC
) AS anon_3
GROUP BY anon_3.asset_id, anon_3.asset_name) AS anon_2 JOIN
(
SELECT substation.data_mtr_body_dga.asset_id AS asset_id
, substation.data_mtr_body_dga.acquisition_date AS acquisition_date
, substation.ai_mtr_body_dga.ai_diagnosis_result AS ai_diagnosis_result
FROM substation.data_mtr_body_dga LEFT OUTER JOIN substation.asset
ON substation.data_mtr_body_dga.asset_id = substation.asset.id
LEFT OUTER JOIN substation.ai_mtr_body_dga
ON substation.data_mtr_body_dga.id = substation.ai_mtr_body_dga.data_mtr_body_dga_id
WHERE substation.asset.company_id = :company_id
AND substation.asset.asset_type = 'MTR'
AND substation.asset.serial_no = ANY (SELECT UNNEST(:available_licenses))
) AS anon_1
ON anon_2.asset_id = anon_1.asset_id
AND anon_1.acquisition_date = anon_2.prev_acquisition_date
LIMIT 1
"""
)
sql_result2 = session.execute(
query_2,
{
"available_licenses": available_licenses,
"company_id": company_id,
},
)
results1 = [rowproxy._mapping for rowproxy in sql_result1]
results2 = [rowproxy._mapping for rowproxy in sql_result2]
end = time.time()
print("****************************************************")
print(f"{end - start:.5f} sec")
print("****************************************************")
responses = {"current": results1[0], "prev": results2[0]}
SQL
복사
[결과] ORM 이 가공한 Raw SQL 로 실행 시
1회시도 (DB Cache 제거) | 2회 (DB Cache 제거) | 3회 (DB Cache 제거) | |
1 try | 4.68825 sec | 4.95818 sec | 4.51720 sec |
2 try | 1.86746 sec | 1.88096 sec | 1.97292 sec |
3 try | 1.83698 sec | 1.87081 sec | 1.87755 sec |
[결과] ORM 으로 실행 시
1회시도 (DB Cache 제거) | 2회 (DB Cache 제거) | 3회 (DB Cache 제거) | |
1 try | 6.62579 sec | 6.28475 sec | 6.25671 sec |
2 try | 5.42588 sec | 5.30851 sec | 4.69481 sec |
3 try | 4.86993 sec | 4.90473 sec | 4.73450 sec |
[결과] Raw SQL 로 실행 시
1회시도 (DB Cache 제거) | 2회 (DB Cache 제거) | 3회 (DB Cache 제거) | |
1 try | 4.37999 sec | 4.64817 sec | 4.29508 sec |
2 try | 1.76666 sec | 1.64863 sec | 1.59068 sec |
3 try | 1.61587 sec | 1.56709 sec | 1.59817 sec |
DB 캐싱에 의한 성능향상을 고려해서 1try 의 경우에 한해서, 비교해 보면 ORM으로 조회했을 때와 Raw SQL로 조회했을 때를 비교해보면 아래와 같습니다.
ORM → SQL 로 변경하는데 소요되는 시간 약 1.67 초 정도 소요
직접 짠 Raw SQL 구조 대비 약 0.28 초 정도 성능 저하
사실 SQL 튜닝 관점에서도 수많은 데이터를 IN 절을 통해서 받도록 하는것은 좋지 못한 행동이지만, ORM이 수많은 파라미터를 IN 절로 받도록 변환하는 과정에서 매우 긴 SQL을 만들게 되고 SQL로 가공하는 시간과 더불어 캐싱 효과를 제대로 누리지 못하게 한 것으로 보입니다.
ORM이 가공한 SQL 로그
AND substation.asset.serial_no IN (%(serial_no_1_1)s, %(serial_no_1_2)s, %(serial_no_1_3)s, %(serial_no_1_4)s, %(serial_no_1_5)s, %(serial_no_1_6)s, %(serial_no_1_7)s
, %(serial_no_1_8)s, %(serial_no_1_9)s, %(serial_no_1_10)s, %(serial_no_1_11)s, %(serial_no_1_12)s, %(serial_no_1_13)s, %(serial_no_1_14)s, %(serial_no_1_15)s
, %(serial_no_1_16)s, %(serial_no_1_17)s, %(serial_no_1_18)s, %(serial_no_1_19)s, %(serial_no_1_20)s, %(serial_no_1_21)s, %(serial_no_1_22)s, %(serial_no_1_23)s
, %(serial_no_1_24)s, %(serial_no_1_25)s, %(serial_no_1_26)s, %(serial_no_1_27)s, %(serial_no_1_28)s, %(serial_no_1_29)s, %(serial_no_1_30)s, %(serial_no_1_31)s
, %(serial_no_1_32)s, %(serial_no_1_33)s, %(serial_no_1_34)s, %(serial_no_1_35)s, %(serial_no_1_36)s, %(serial_no_1_37)s, %(serial_no_1_38)s, %(serial_no_1_39)s
, %(serial_no_1_40)s, %(serial_no_1_41)s, %(serial_no_1_42)s, %(serial_no_1_43)s, %(serial_no_1_44)s, %(serial_no_1_45)s, %(serial_no_1_46)s, %(serial_no_1_47)s
, %(serial_no_1_48)s, %(serial_no_1_49)s, %(serial_no_1_50)s, %(serial_no_1_51)s, %(serial_no_1_52)s, %(serial_no_1_53)s, %(serial_no_1_54)s, %(serial_no_1_55)s
, %(serial_no_1_56)s, %(serial_no_1_57)s, %(serial_no_1_58)s, %(serial_no_1_59)s, %(serial_no_1_60)s, %(serial_no_1_61)s, %(serial_no_1_62)s, %(serial_no_1_63)s
, %(serial_no_1_64)s, %(serial_no_1_65)s, %(serial_no_1_66)s, %(serial_no_1_67)s, %(serial_no_1_68)s, %(serial_no_1_69)s, %(serial_no_1_70)s, %(serial_no_1_71)s
, %(serial_no_1_72)s, %(serial_no_1_73)s, %(serial_no_1_74)s, %(serial_no_1_75)s, %(serial_no_1_76)s, %(serial_no_1_77)s, %(serial_no_1_78)s, %(serial_no_1_79)s
, %(serial_no_1_80)s, %(serial_no_1_81)s, %(serial_no_1_82)s, %(serial_no_1_83)s, %(serial_no_1_84)s, %(serial_no_1_85)s, %(serial_no_1_86)s, %(serial_no_1_87)s
, %(serial_no_1_88)s, %(serial_no_1_89)s, %(serial_no_1_90)s, %(serial_no_1_91)s, %(serial_no_1_92)s, %(serial_no_1_93)s, %(serial_no_1_94)s, %(serial_no_1_95)s
, %(serial_no_1_96)s, %(serial_no_1_97)s, %(serial_no_1_98)s, %(serial_no_1_99)s, %(serial_no_1_100)s, %(serial_no_1_101)s, %(serial_no_1_102)s, %(serial_no_1_103)s
, %(serial_no_1_104)s, %(serial_no_1_105)s, %(serial_no_1_106)s, %(serial_no_1_107)s, %(serial_no_1_108)s, %(serial_no_1_109)s, %(serial_no_1_110)s, %(serial_no_1_111)s
, %(serial_no_1_112)s, %(serial_no_1_113)s, %(serial_no_1_114)s, %(serial_no_1_115)s, %(serial_no_1_116)s, %(serial_no_1_117)s, %(serial_no_1_118)s, %(serial_no_1_119)s
, %(serial_no_1_120)s, %(serial_no_1_121)s, %(serial_no_1_122)s, %(serial_no_1_123)s, %(serial_no_1_124)s, %(serial_no_1_125)s, %(serial_no_1_126)s, %(serial_no_1_127)s
, %(serial_no_1_128)s, %(serial_no_1_129)s, %(serial_no_1_130)s, %(serial_no_1_131)s, %(serial_no_1_132)s, %(serial_no_1_133)s, %(serial_no_1_134)s, %(serial_no_1_135)s
, %(serial_no_1_136)s, %(serial_no_1_137)s, %(serial_no_1_138)s, %(serial_no_1_139)s, %(serial_no_1_140)s, %(serial_no_1_141)s, %(serial_no_1_142)s, %(serial_no_1_143)s
, %(serial_no_1_144)s, %(serial_no_1_145)s, %(serial_no_1_146)s, %(serial_no_1_147)s, %(serial_no_1_148)s, %(serial_no_1_149)s, %(serial_no_1_150)s, %(serial_no_1_151)s
, %(serial_no_1_152)s, %(serial_no_1_153)s, %(serial_no_1_154)s, %(serial_no_1_155)s, %(serial_no_1_156)s, %(serial_no_1_157)s, %(serial_no_1_158)s, %(serial_no_1_159)s
....
....
...
SQL
복사
ORM이 가공한 SQL 로그
AND a.serial_no = ANY (SELECT UNNEST(%(available_licenses)s))
JavaScript
복사
*비고
이 글을 작성하기까지 5~6 번의 수정이 이루어 졌으며, 시간대에 따른 트래픽 등 불안정한 네트워크로 인해, 백엔드, 데이터베이스 서버간 데이터 전송 비용 및 측정 시간의 오차가 상당히 발생하여 데이터의 신뢰성이 무너지게 되었습니다.
최종적으로 해당 글은 백엔드 서버와 데이터베이스 서버간 로컬망에서 랜선 연결을 통해 측정한 데이터이며, DB 데이터 모수도 그저 5500 여건의 데이터를 가지고 측정한 데이터이기에, 실제 운영 환경에서는 좀 더 극적인 효과를 기대할 수 있을 것으로 기대합니다.
6. 마치며
ORM 진영과 SQL 진영의 열띤 토론 배틀에 참여했었던 1인으로서, 개인적으로 2년 넘게 고민해온 주제 였습니다. 이 글의 내용만 본다면 SQL진영의 승리처럼 보일 수 있지만, 이 글을 작성하고 준비하면서 새로운 인사이트를 얻게 되었습니다.
바로 ORM 만이 가지고 있는 ‘특별한 장점’이 있다는 점과 DB 연산 비용 못지 않게 중요한 요소가 바로 ‘네트워크 비용' 이라는 점 입니다.
또한 이런 결과값은 어디까지나 OLAP 시스템 관점에서 작성한 글로, 복잡하지 않은 쿼리를 가진 OLTP 시스템이라면 ORM 도 충분히 사용하기 좋은 매력적인 도구라고 생각됩니다.
다음 편에는 ORM 이 가지고 있는 장점과, 성능 개선포인트에 대해 정리되어 있으니 함께 확인해보세요!
이 글을 쓴 사람

장 진 수 | guardione substation 팀
substation 팀
substation 팀제조 분야 대기업에서 수많은 설비 데이터를 가공하고 운영해왔습니다.
CTO (Chief Technology Officer)를 꿈꾸며 마주하는 이슈를 풀어가기 위해 아키텍처와 컨셉을 고민하고, 이런 노력이 제품에 반영될 수 있는 환경을 찾아 스타트업인 원프레딕트에 합류하게 되었습니다.
장진수님이 쓴 또 다른 글 보러가기