
 진동 신호를 통해 컴프레셔 건전성 상태 분류: End to End Model
진동 신호를 통해 컴프레셔 건전성 상태 분류: End to End ModelGoal
모터와 스크류에서 획득된 진동신호를 컴프레서의 건전성 상태와 직결하는 End-to-End 분류 모델을 학습/활용 해보기
Background
도메인 지식을 최대한 배제한다고 했을 때 가장 쉬운 접근방법은 End-to-End 모델을 구축하는 것입니다. 즉 주어진 진동신호를 별다른 처리 없이(혹은 최소한의 정규화(Normalization)만을 수행하여) 딥러닝 모델의 입력 신호로 사용하고 모델의 출력값으로 저희가 목표로 하는 컴프레서의 건전성 상태를 매핑(Mapping)하는 것이죠. 이를 위해서는 강력한 하나의 전제가 필요합니다.
주어진 데이터의 양이 모델을 학습하기에 충분히 많다
이러한 전제만 만족된다면 오히려 인간의 어떠한 선입견(Preconception/Bias)도 없이 순수하게 목적함수에 귀속되는 모델이 학습될 수 있고, 실제 다양한 사례에서 오히려 더 높은 성능을 보이는 것이 확인되었습니다. 대표적인 사례가 바로 그 유명한 알파고입니다. 2016년 이세돌프로와의 경기에서 사용된 모델은 알파고 버전 18 입니다. 이 모델은 수많은 경우의 수를 학습하였지만 그 학습과정에는 인간의 기보가 대표적인 레퍼런스로 활용되었습니다. 즉 인간의 선입견이 학습 중에 반영된 모델이라고 할 수 있습니다. 일종의 인류의 바둑 역사의 모든 바둑 기사들이 알파고 버전 18 의 스승이라고 볼 수 있지요. 하지만 불과 1년 뒤인 2017년, 딥마인드는 알파고 제로라는 무시무시한 모델을 새롭게 선보입니다. 알파고 제로에서는 그 어떠한 인간의 기보도 학습과정에 사용되지 않았습니다. 순수하게 바둑돌의 현황과 바둑 경기에서 승리한다는 목적만을 설정한 End-to-End 학습을 적용한 것이지요. 그 결과는 어땠을까요?
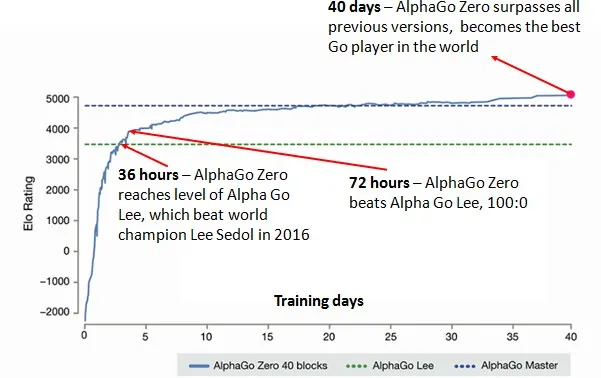
알파고 버전 18(초록색 점선; AlphaGo Lee)과 알파고 제로(파란색 실선)의 성능비교를 나타낸 그래프입니다. 학습이 진행되기 시작하면서 알파고 제로의 성능이 무섭게 향상되는 것이 보입니다. 특히 36시간이 지나는 시점에서 알파고 제로가 알파고 버전 18의 성능을 추월하는 것이 보이는데요, 72시간이 지난시점에서는 무려 100대 0이라는 잔혹한 성적으로 알파고 제로가 알파고 버전 18을 압도하는 것이 보입니다.
Preparation
자, 그렇다면 과연 우리가 End-to-End 학습을 진행할 만큼 충분한 데이터를 확보하였는지, 또 그 데이터를 어떻게 활용할 것인지에 대한 전략을 검토해보아야 합니다. 먼저 이전 포스트에서 설명드렸던 저희에게 주어진 학습 데이터를 상세히 살펴보면 다음과 같습니다.
데이터셋 상세정보
Status | Event | Length | # of available subsamples |
Bearing | 1 | 1,800s | 18,979,199 |
Looseness | 1 | 609s | 6,521,295 |
Normal | 1 | 1,485s | 15,657,839 |
Unbalance | 1 | 1,117s | 11,779,755 |
Losseness-High | 1 | 416s | 4,384,195 |
Bearing | 2 | 3,890s | 41,020,377 |
Looseness | 2 | 3,070s | 32,365,831 |
Unbalance | 2 | 2,852s | 30,082,031 |
Normal | 3 | 5,017s | 52,907,683 |
Unbalance | 3 | 2,240s | 23,616,451 |
데이터를 하나하나 자세히 열어보면 생각보다 데이터의 양이 상당히 많은 것을 알 수 있습니다. 특히 End-to-End 학습 전략을 고려할 때 저희는 입력신호를 0.012초씩 자르게 되니 실질적으로 가용한 sub-sampled 데이터는 엄청나게 많은 양을 확보할 수 있습니다. 실제로 구현 가능한 모든 sub-sample의 갯수는 237,314,656개(!!), 중복을 배제한다고 해도 1,854,020개의 데이터 샘플을 얻을 수 있습니다. 문제의 난이도에 따라서 달라질 수 는 있지만, 이정도 데이터라면 End-to-End 훈련을 진행하기엔 충분해 보일 수 있습니다.
Batch Design
그러면 본격적으로 훈련을 진행할 때 고려해야할 디테일들을 논해보겠습니다. 그 중에서도 특히 데이터를 어떻게 훈련과정에 노출시킬지에 대한 고민이 가장 우선되는데요, 보통 이미지 훈련의 경우에는 그림들이 모두 독립적으로 존재하지만 지금 저희는 큰 뭉텅이 신호에서 일부 신호를 sub-sampling 해야합니다.
가장 쉬운 방식은 모든 가능한 sub-sample을 만들어 놓고, 이들을 섞어서 배치를 만드는 방법입니다. 일반적인 Batch-Epoch 디자인에도 가장 적합하고 데이터를 낭비없이 모두 사용할 수 있다는 장점도 있습니다. 하지만 치명적인 문제가 두가지 발생할 수 있는데요, 첫번째로는 데이터가 너무 많다는 것입니다. 앞에서 언급한것처럼 활용가능한 sub-sample의 갯수는 237,314,656개, 중첩을 배제한다고 해도 1,854,020개의 데이터를 갖게 됩니다. 이 데이터를 모두 훈련에 활용한다면 1 Epoch에 소요되는 시간이 너무 오래걸리게 됩니다. 또다른 문제로는 각 상태에 따른 데이터량이 불균형(Imbalance)하다는 점도 있습니다. 특히 Normal 상태의 데이터가 총 5,500s 정도인 반명 Losseness-High의 데이터양을 416s정도로 1/10에 불과합니다. 만약 단순하게 랜덤셔플링을 통해 배치를 구성한다면 대부분의 배치에서는 Normal에 편향된 훈련이 이뤄질 가능성이 높습니다.
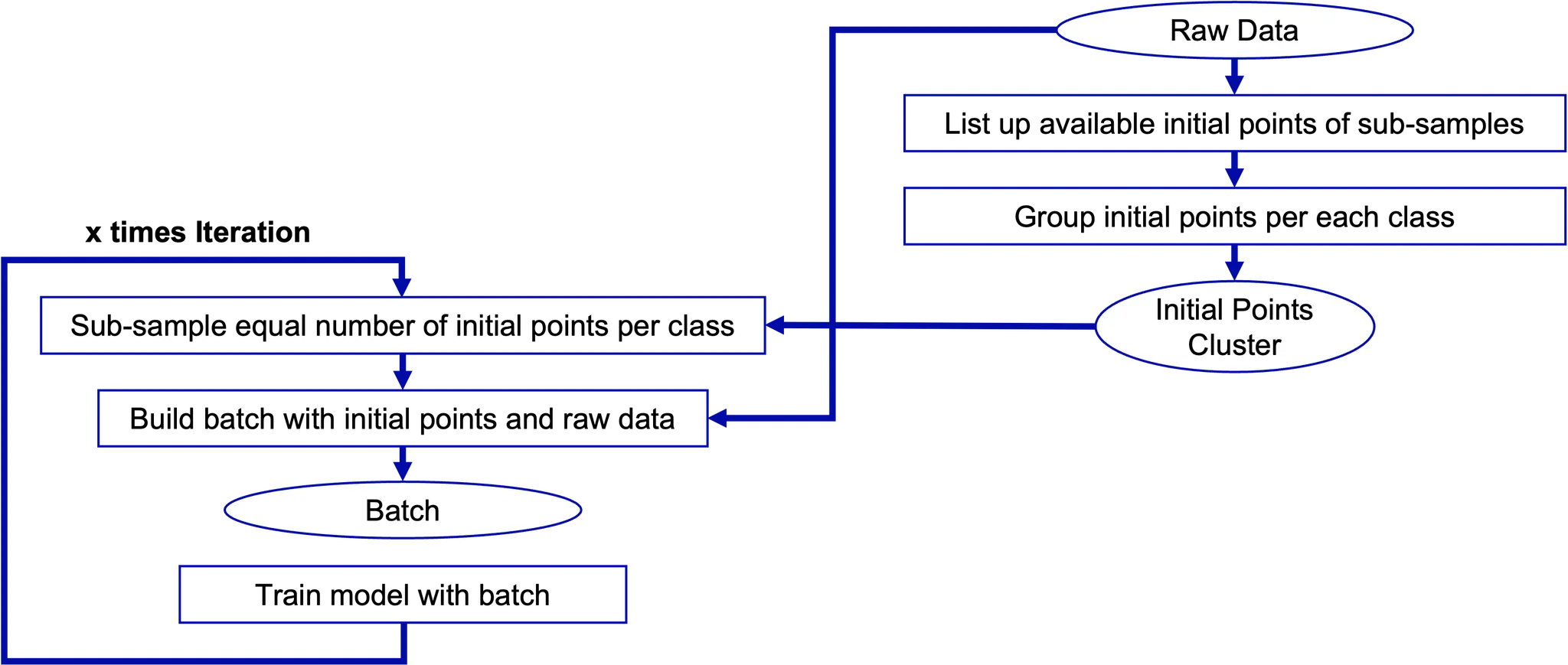
따라서 저희는 Batch-Epoch 디자인 보다는 Batch-Iteration 전략을 취하기로 했습니다. 즉 Batch Sampling을 저희가 정한 Iteration 만큼 수행하는 것이지요. 이 경우 누락되는 데이터가 발생할 수 있다는 단점이 있지만 훈련 양을 보다 자유롭게 선택할 수 있다는 이점이 있습니다. 또 모든 Batch Sampling에서는 각 상태의 데이터를 동일량 샘플하도록 하였습니다. 예를 들어 전체 Batch Size가 100이라면 20개는 Normal에서, 20개는 Unbalance에서 샘플링하는 식이지요. 이를 통해 훈련 과정에서 소수의 데이터도 충분히 노출시켜서 특정 상태에 편향되는 것을 방지하고자 하였습니다. 다만 이렇게 할 경우 데이터량이 적은 클래스에 대해 Overfitting이 발생할 수 있는데요, 다행히도 저희는 충분히 많은 데이터를 가지고 있기때문에 이런 위험성은 낮을것이라고 예상하였습니다.
Network Design
이제 데이터를 어떻게 사용할지 정했으니 이제 네트워크 아키텍처를 디자인 해보도록 허겠습니다. 기본적인 네트워크의 아키텍처는 이미지 처리에서 많이 활용되는 CNN(Convolutional Neural Network)을 활용하기로 하였습니다. 즉 진동신호를 이미지처럼 다루겠다는 의미인데요, 사실 다소 의아할 수 있는 결정입니다. 공간상의(Spatial) 정보를 다루기 위해 고안된 CNN을 시간상에(Time-wisely) 정의된 진동신호에 사용한다는 점인데요, 아래의 이유를 함께 살펴보았으면 좋겠습니다.
- 일반적으로 CNN은 DNN보다 적은 weights를, RNN보다 많은 weights를 사용한다.
- 동일한 weights 양을 사용한다고 할 때 CNN은 RNN보다 학습이 간편하고 속도가 빠르다.
- CNN은 다른 구조에 비해 Pre-trained Model이 많이 배포되어 있다.
- (무엇보다도) CNN은 기본적으로 kernel-wise computation이기 때문에 Filter Design으로 해석 가능하다.
앞의 세가지 조건보다 마지막 조건을 가장 주의깊게 살펴볼까요? 회전체의 신호 분석에서, 특히 그 회전체가 등속 상태에(Stationary Rotation) 있을 때 가장 중요한 것은 주파수 성분 분석입니다. 시간 도메인에서 신호를 아무리 들여다봐도 보이지 않는 특징이 주파수 도메인으로 변환될 경우 그 특징들이 뚜렷하게 나타나기 때문인데요, 무엇보다도 특성주파수(Characteristic Frequency)라고 부르는 주파수 성분이 고장 진단 분석에 몹시 중요한 힌트를 주곤 합니다. (대표적인 특성 주파수로는 회전체의 회전주파수가 있습니다.)
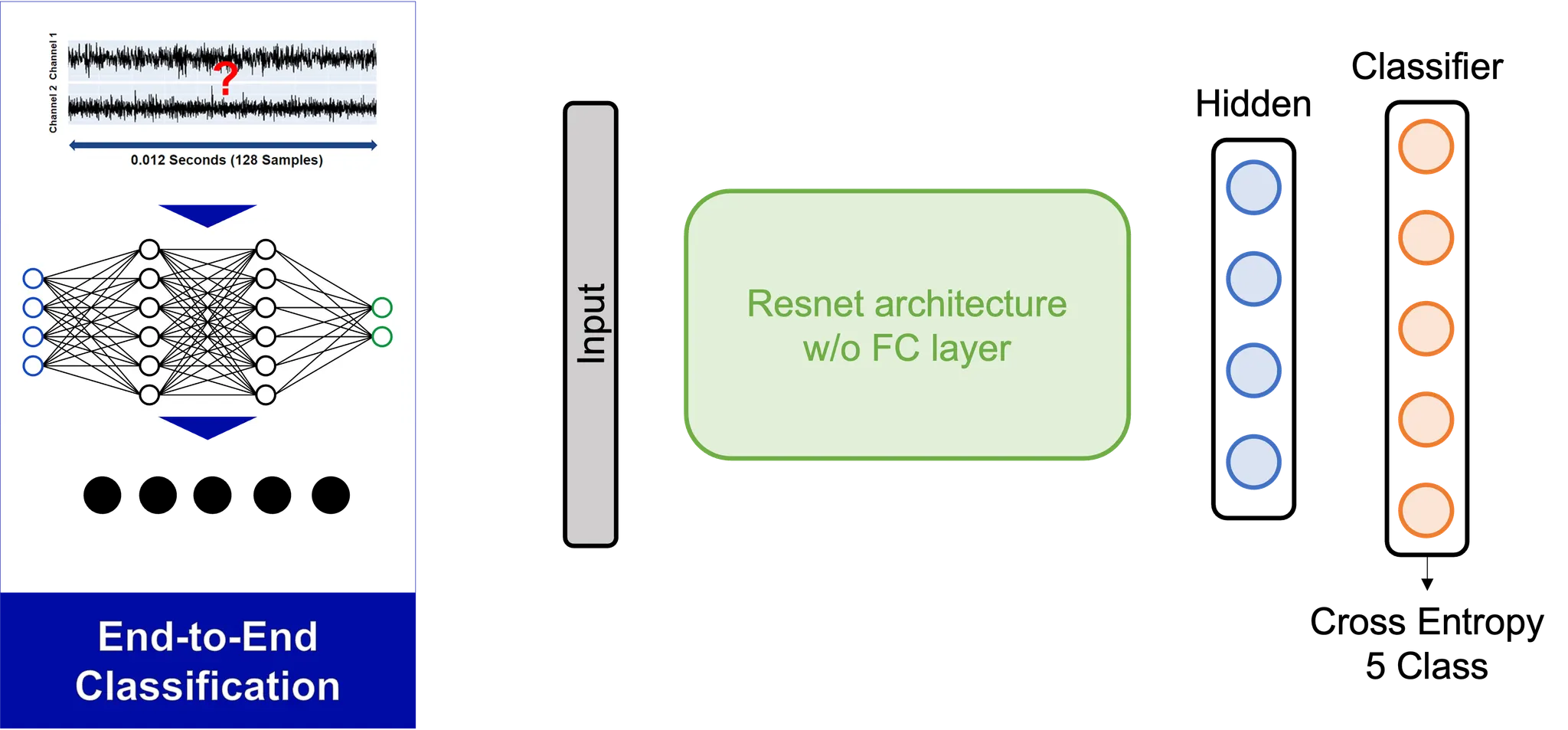
자 그러면 다시 1-Dimensional CNN으로 돌아와서, 우선 다음과 같은 End-to-End 모델을 고려해볼 수 있습니다. 입력값으로는 주어진 0.012초의 두 채널 데이터를 사용한다고 할 때, 이는 2채널짜리 이미지로, 즉 128x1x2 (width x height x channel) 이미지로 생각할 수 있습니다. 기존에 이미지에서 pre-train 되어있는 모델을 활용한다고 할 때, 이를 위해서는 다음의 두가지 조건이 만족되어야 합니다.
조건 1. 입력되는 채널이 3채널이어야 한다.
조건 2. 이미지의 크기가 5x5이상이어야한다.
먼저 조건 1.은 반드시 만족되어야하는 조건입니다. 그렇지 않을 경우에는 차원이 일치하지 않아 연산 자체가 수행될 수 없습니다. 반면 조건 2의 경우에는 꼭 필요하지는 않은 조건입니다. zero-padding 과 같은 방법을 통해 무리 없이 연산을 수행할 수 있기 때문이지요.
우선 저희는 문제를 단순히 하기 위해 다음의 전처리를 진행하여 입력 데이터를 사용하였습니다.
- 데이터의 채널을 높이로 사용한다. (128x1x2 → 128x2x1)
- 높이방향으로 데이터를 3회 반복하여 덧붙인다 (concatenate) (128x2x1 → 128x6x1)
- 채널방향으로 데이터를 3회 반복하여 덧붙인다 (128x6x1 → 128x6x3)
Result and Evaluation
과연 그렇다면 결과는 어떻게 나왔을까요? 우선 Confusion Matrix를 이용해서 성능을 평가해보면 다음과 같습니다. [0:Normal, 1:Unbalance, 4:Bearing Fault, 2: Belt-Looseness, 3: Belt-Looseness High)
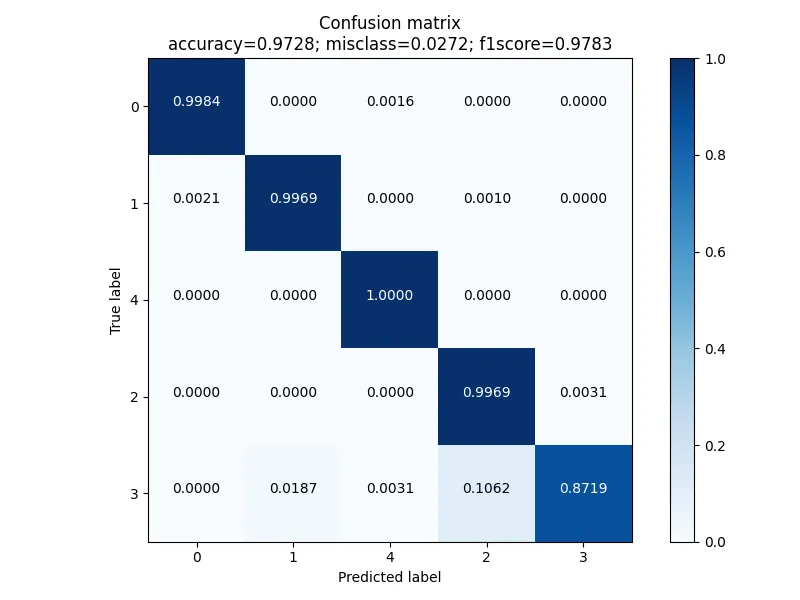
주목할 만한 점은 성능이 나쁘지 않다는 것입니다. Accuracy가 97.28%나 되고, F1스코어도 0.9783이나 됩니다. 다만 한가지 아쉬운 것은 바로 Belt-looseness의 성능인데요, 결론적으로 보면 저희 모델은 Belt-looseness의 심각한 수준을 분석하는 것에서 상대적으로 아쉬운 성능을 보입니다. (그럼에도 87% 이상의 높은 성능을 보이기는 합니다.)
사실 처음에는 이 정도 성적이면 나쁘지 않다고 생각했었습니다. 실제로 Leader Board에서 2위 정도의 상위권 성적을 차지하기도 했구요. 하지만 대회가 점점 막바지에 치달아가면서 점차 다른 팀들의 성적이 저희의 모델을 바짝 추격해오기 시작했습니다.
그래서 고민 끝에 저희는 확실한 승리를 위해 99.9% Accuracy를 목표로 모델을 보다 발전시켜보기로 했습니다. 그러려면 아무래도 약점으로 지적되는 Belt-Looseness를 어떻게 더 정확히 진단할 수 있을지가 관건이였는데요, 다음 포스팅에서는 이 문제를 해결하기 위한 Hierarchical 모델을 소개해드리도록 하겠습니다.
PHMAP 2021 Data Challenge Project Stories
이 글을 쓴 사람

김 수 호 | Product1팀
행동보다 말이 앞서는 INTP Data Scientist 입니다.
정보의 늪에서 맹목적으로 행동하기 보다는 먼저 고민하고 함께 의논하는 개발자가 되고 싶습니다.
원프레딕트 홈페이지
https://onepredict.ai/
원프레딕트 블로그
https://blog.onepredict.ai/
원프레딕트 기술 블로그
https://tech.onepredict.ai