
 진동 신호를 통해 컴프레셔 결함 심각도 추정: Hierarchical Model
진동 신호를 통해 컴프레셔 결함 심각도 추정: Hierarchical ModelGoal
모터와 스크류에서 획득된 진동신호를 활용하여 컴프레서의 건전성 상태 진단(Classification)과 결함 심각도 추정(Regression)을 동시에 수행하는 Hierarchical 모델 학습/활용 해보기.
Background
먼저 저번 포스팅의 결과를 복기해보도록 하겠습니다. Resnet 아키텍처의 1d CNN 기반 진단 구분 성능은 아래와 같았습니다. [0:Normal, 1:Unbalance, 4:Bearing Fault, 2: Belt-Looseness, 3: Belt-Looseness High)
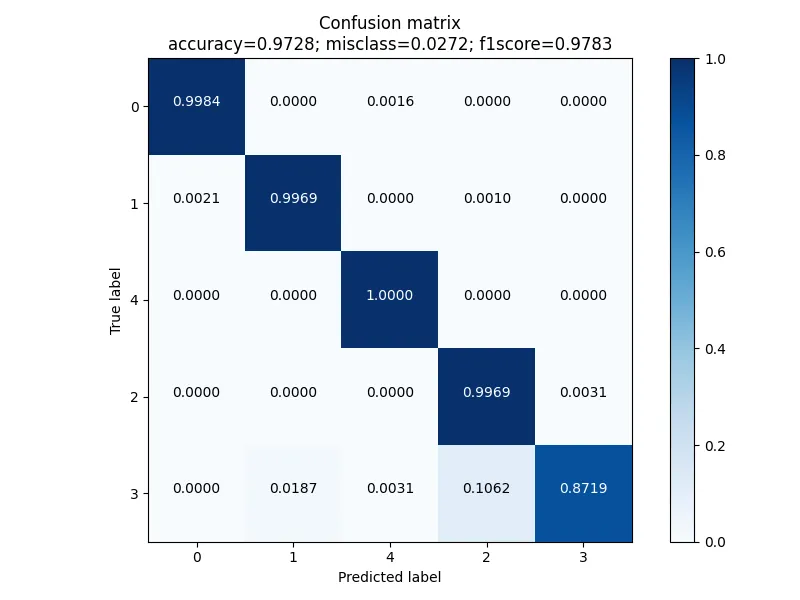
이전 포스팅에서 발견된 문제는 바로 Belt-looseness의 진단 성능이었는데요, 바로 특히 Belt-looseness와 Belt-Looseness High를 잘 구분하지 못한다는 것입니다. 사실 원인은 쉽게 유추할 수 있는데요, 바로 이 둘을 구분하는 것은 Classification 문제에 부합하지 않기 때문입니다.
제안된 End-2-End 모델에서 Cross-Entropy기반의 Classification 문제는 서로 독립적인(Independent) 분포를 가정합니다. 즉 모집단이 다르다는 것인데요, 각 분포간의 상관관계가 없다면 이를 분류하기 위한 경계(Decision Boundary)를 학습하는 것이 상대적으로 용이합니다. 하지만 저희가 마주한 문제의 경우에는 어떨까요? 과연 Belt-Looseness와 Belt-Looseness High를 서로 다른 모집단이라고 볼 수 있을까요?
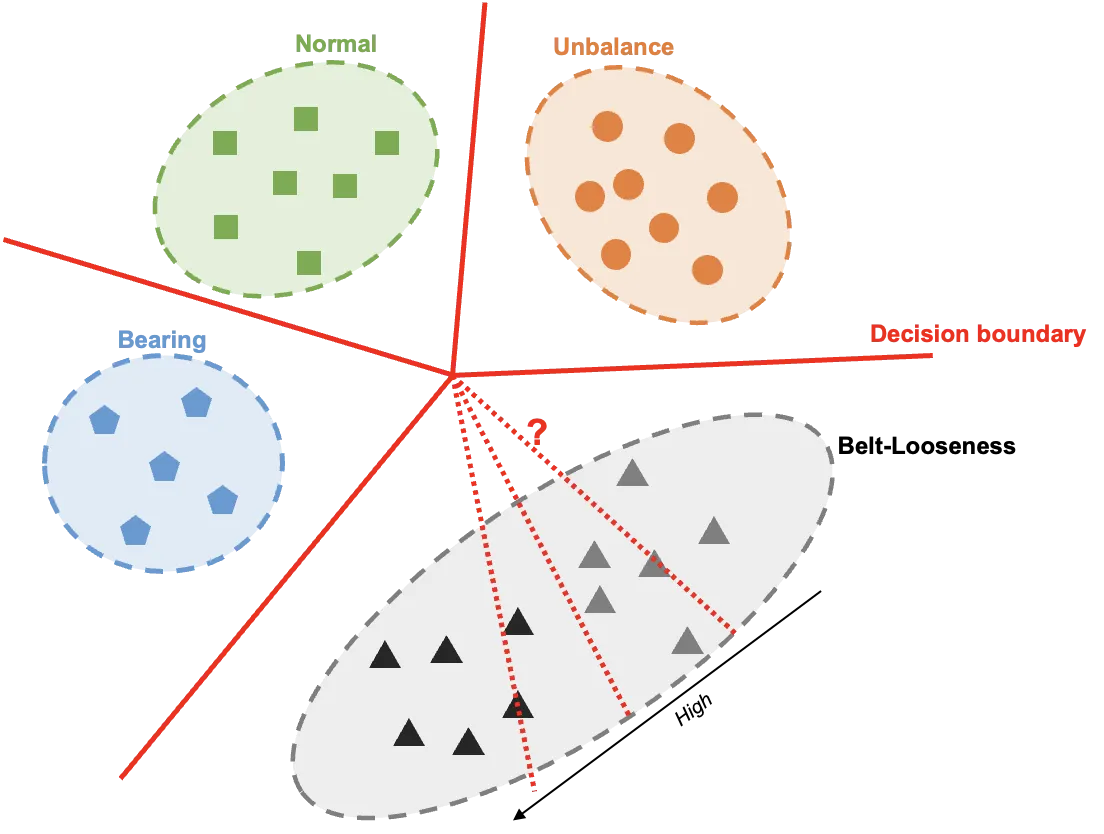
Belt-Loosseness와 Belt-Loosseness High를 서로 다른 분포라고 바라볼 수 있을까요?
저희의 결론은 그렇지 않다는 것입니다. 모집단이라는 것이 결국 정의되기 나름이겠지만, 하나의 문제에서는 동일한 정의, 동일한 위상으로 모집단의 구분이 적용되어야합니다. 예를 들어 Normal과 Bearing, Normal과 Unbalance모드의 분포간 거리를 생각해보았을때 이것이 Belt-Looseness와 Belt-Looseness High의 분포 거리와 유사할까요? 물론 우리는 전자의 분포간 거리가 후자의 분포간 거리보다 월등히 클 것이라고 쉽게 유추할 수 있습니다. 요약하면 저희가 각 모드별로 고장 모드를 정의할 때 각 분포 정의의 위상이 다르다고 볼 수 있는 것이지요. 따라서 이 두 서로다른 위상은 하나의 문제에서 동시에 풀고자 하는 시도가 썩 적합한 방법이 아니라고 판단할 수 있습니다.
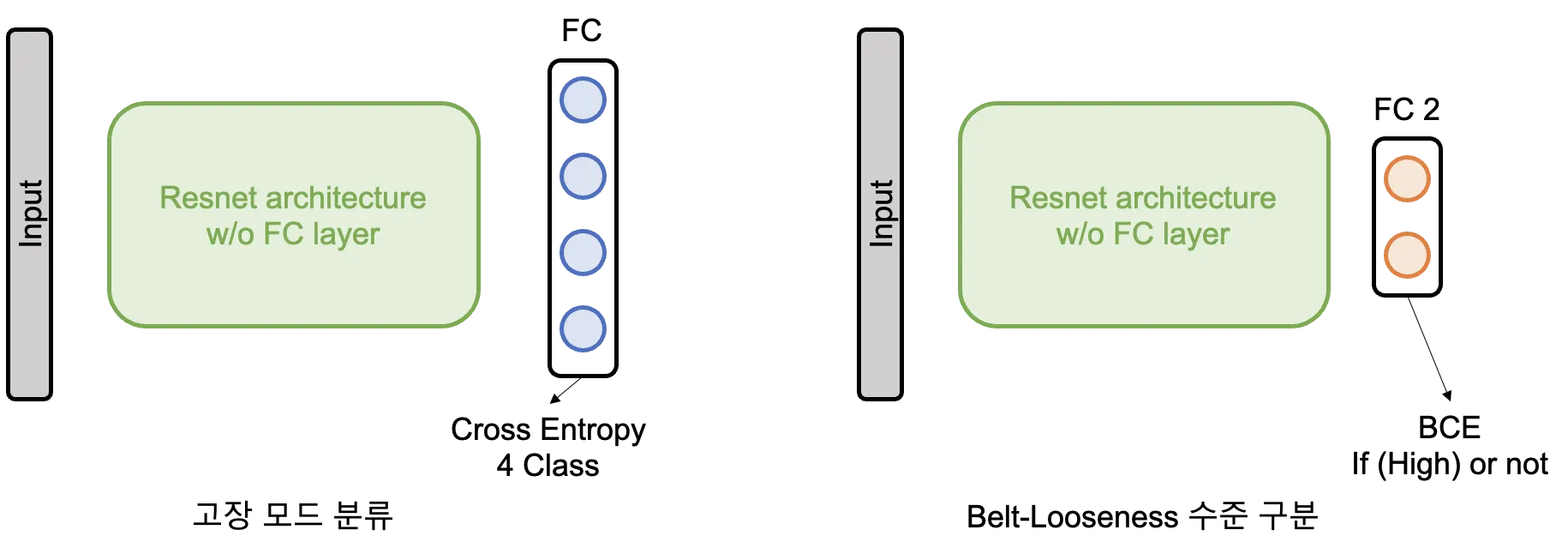
그렇다면 가장 쉬운 방법은 무엇일까요? 우선 태스크를 단순하게 분리하는 방법이 있습니다. 첫번째 태스크는 주어진 데이터가 Normal/Bearing/Unbalance/Belt-Looseness 중 어느 고장모드에 해당하는지를 맞추는 것이고, 두번째 태스크는 Belt-Looseness의 수준이 High인지 여부를 판단하는 것입니다.
자 그러면 전체적인 문제를 다시 한번 살펴볼까요? PHM은 크게 4가지 단계가 있습니다.
1. 고장 감지 (Anomaly Detection)
2. 고장 진단 1 (Fault Diagnosis - Classification)
3. 고장 진단 2 (Fault Diagnosis - Severity Estimation)
4. 고장 예측 (Fault Prognosis)
이렇게 놓고 보니 사실 이번 챌린지가 단순한 PHM의 한 주제를 다루기보다는 1번 태스크부터 3번 태스크까지 PHM의 전반적인 태스크를 요구하고 있다는 것이 밝혀졌습니다. (심지어 나중에 포스팅 될 미래신호의 Regression 문제는 4번 태스크에 해당하니 사실상 PHM의 모든 주제를 요구하고 있다고 볼수 있겠군요!)
다시 본론으로 돌아와서 그러면 이제 우리는 두가지 네트워크를 각각 독립적으로 학습하면 되겠다는 결론에 도달합니다. 먼저 고장 모드를 분류하는 네트워크를 잘 학습시키고, 그중 Belt-Looseness에 해당하는 데이터들만 다시 Belt-Looseness 수준을 구분하는 네트워크에 학습시키는 것이지요. 그러면 저희는 Belt-Looseness의 수준까지 잘 분류해내는 목적에 도달할 수 있겠지요. 하지만 한가지 더 고려해야할 것이 있습니다. 과연 두 네트워크를 서로 독립되게 훈련하는 것이 좋은 아이디어일까요? 이미 고장에 관련된 특징을 추출하도록 잘 훈련되어 있는 네트워크가 있는데 이와 독립된 네트워크를 처음부터 새로 훈련하는것이 효율적인 방법일까요? Belt-Looseness라는 제한된 환경의 데이터만으로도 네트워크가 고장 특징을 잘 추출할 수 있도록 훈련될 수 있을까요? 이런 접근방법은 Belt-Looseness 수준을 구분하는 네트워크를 훈련 데이터에 오버피팅 시키지 않을까요?
그래서 저희는 기존의 네트워크를 활용하면서도 두가지 태스크를 동시에 수행하도록 네크워크를 디자인하게 되었습니다.
Hierarchical Neural Network
기존의 Hierarchical 네트워크는 서로 다른 위상의 피처를 활용하기 위해 고안되었습니다. 입력된 데이터에서 추출된 Low-level Feature를 보존하고, 더 연산이 진행된 High-level Feature를 함께 사용해서 최종적인 결과를 도출하겠다는 아이디어인데요, 이런 측면에서 보면 Low-level feature를 다음 레이어의 결과에 그대로 전달하는 Residual-Connection의 컨셉과도 비슷합니다.
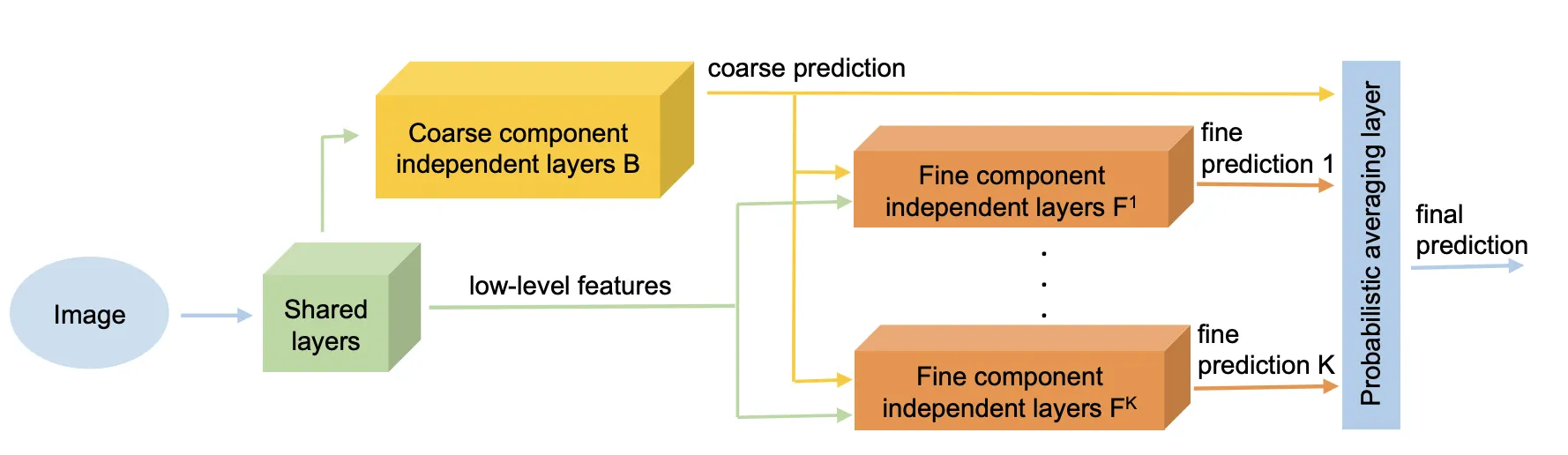
(출처: Z. Yan et al., “HD-CNN: Hierarchical Deep Convolutional Neural Network for Large Scale Visual Recognition,” in Computer Vision and Pattern Recognition, 2015, pp. 2740–2748)
저희는 이걸 조금 다르게 해석해보았습니다. 어쩌면 정말 PHM의 태스크에 입각한 Naive한 접근방식이었는데요, 전제는 간단합니다.
고장 심각도 진단보다는 고장 분류가 더 쉽지 않을까?
지금와서 보면 정말 오류가 많은 전제입니다만, 이런 전제를 깔고 나면 고장 분류는 Low-level feature로, 고장 심각도 진단은 Low-level feature와 High-level feature를 함께 사용해서 풀수 있겠다는 결론에 도달하게 됩니다. 그러면 이제 저희는 다음과 같은 네트워크를 구성할 수 있게 되죠.
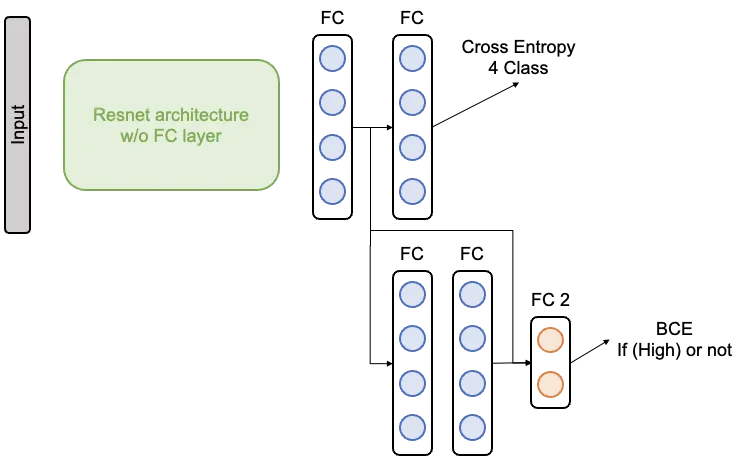
이 네트워크에서는 입력된 신호로부터 Resnet 기반의 Low-level feature가 추출됩니다. 추출된 피처는 그대로 고장 모드 분류 문제에 활용됩니다. 한편 Low-level feature 는 다시한번 연산을 거듭하며 High-level Feature로 변환됩니다. 그리고 이 Low-level Feature는 High-level Feature와 함께 고장의 심각도를 평가하는 태스크에 활용됩니다. 이러한 일련의 과정은 동일한 학습 Phase에서 훈련되고, 따라서 네트워크는 다양한 환경에 노출되며 고장에 관련된 특성인자를 추출할 수 있도록 훈련될 수 있습니다.
Result and Evaluation
과연 그렇다면 결과는 어떻게 나왔을까요? 우선 Confusion Matrix를 이용해서 성능을 평가해보면 다음과 같습니다. [0:Normal, 1:Unbalance, 4:Bearing Fault, 2: Belt-Looseness, 3: Belt-Looseness High)
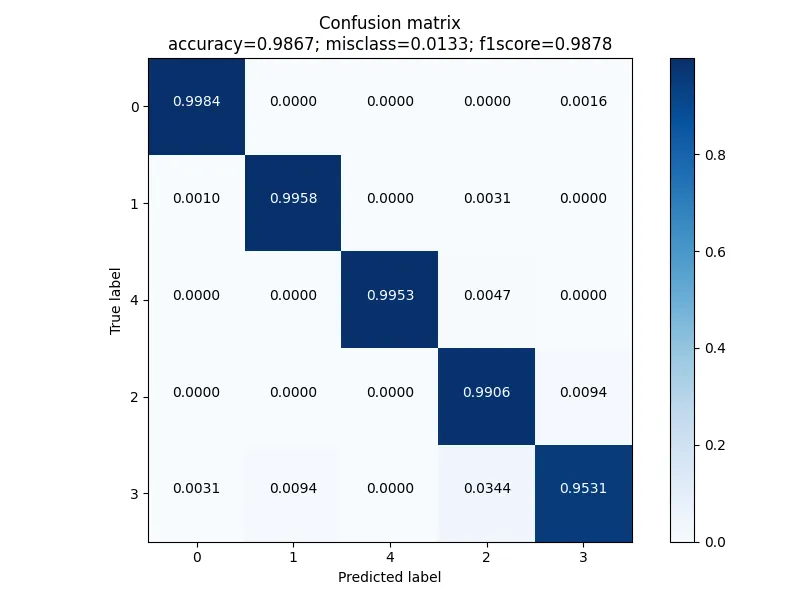
완전하진 않지만 성능이 소폭 향상되었습니다. Accuracy는 97.28%에서 98.67%로 상승했고 F1 스코어도 0.9783에서 0.9878로 향상되었습니다. 특히 주목할만한 부분은 여전히 완전하진 않지만 Belt-Looseness의 수준을 판단하는 성능이 상당히 좋아졌다는 것입니다. 이전에는 87%정도의 성능이었는데 이제 95~99%정도의 성능을 보이니까 말이죠. 이 결과를 가지고 저희는 분류 성능 1등을 탈환할 수 있었습니다. 바로 마지막 주에 돌입하기 전까지 말이죠.
마지막 주에 돌입하자 모든 팀들이 극도의 최적화 싸움을 벌이기 시작했습니다. 모든 팀은 매일 소수점 수준의 성능 향상을 기록하기 시작했고, 모두가 정확도 98~99, F1 스코어 0.98~0.99 수준을 왔다갔다하기 시작했습니다. 최종 랭킹을 매길때에는 기존의 테스트셋이 아닌 제 3의 테스트셋이 사용되기 때문에 이대로라면 실제 최종 평가에서 순위가 뒤바뀔 위험이 있는 것이지요. 이제 남아있는 저희의 과업은 어떻게 하면 이 성능을 제 3의 테스트셋에 대해서도 유지하면서도 극도의 성능 향상을 이뤄내는가였습니다.
다음 포스팅에서는 마지막 마무리를 위한 Ensemble 모델을 소개해드리며 모델의 강건함을 확보하고 성능을 극향상 시켰던 경험을 소개해드리도록 하겠습니다.
PHMAP 2021 Data ChallengeProject Stories
이 글을 쓴 사람

김 수 호 | Product1팀
행동보다 말이 앞서는 INTP Data Scientist 입니다.
정보의 늪에서 맹목적으로 행동하기 보다는 먼저 고민하고 함께 의논하는 개발자가 되고 싶습니다.
원프레딕트 홈페이지
https://onepredict.ai/
원프레딕트 블로그
https://blog.onepredict.ai/
원프레딕트 기술 블로그
https://tech.onepredict.ai